Одной из ключевых технологий для анализа данных и принятия бизнес-решений являются кубы данных OLAP. Их многомерная структура предоставляет возможность эффективного и глубокого анализа различных аспектов бизнеса. Однако для максимальной эффективности использования кубов OLAP необходимо учитывать их особенности и оптимальные стратегии применения.

Эти структуры данных, специально разработанные для аналитических задач, позволяют эффективно организовывать и анализировать информацию из различных источников, обеспечивая быстрый доступ к ключевым показателям и сведениям.
В данной статье мы рассмотрим особенности использования кубов данных OLAP, их преимущества, недостатки, а также оптимальные стратегии применения для получения максимальной пользы от анализа данных.

Что такое куб данных
Куб данных представляет собой концепцию, разработанную для облегчения анализа больших объемов информации в рамках бизнес-аналитики. Этот инструмент агрегирует данные по различным измерениям, таким как время, местоположение, товар и другие параметры, чтобы предоставить пользователям полную картину их бизнес-процессов. Суть куба данных заключается в том, чтобы предоставить быстрый и удобный доступ к информации, необходимой для принятия стратегических решений.
Существует два основных контекста, в которых используются кубы данных. Во-первых, это предварительно агрегированные таблицы в реляционных базах данных, что позволяет избежать медленных оперативных запросов и улучшить производительность. Во-вторых, это объекты данных в специализированных системах OLAP (Online Analytical Processing), которые обеспечивают еще более широкие возможности анализа и визуализации данных.
Одной из ключевых особенностей кубов данных является их способность быстро анализировать и суммировать большие объемы данных за счет использования специализированных структур данных. Кубы OLAP, например, обеспечивают возможность работы с многомерными данными, что позволяет пользователям проводить анализ данных с различных точек зрения и получать ответы на разнообразные вопросы.
Для бизнес-аналитиков и разработчиков ПО, работающих с кубами OLAP, существует возможность создания настраиваемых и расширяемых моделей данных, основанных на инфраструктуре хранилища данных. Это позволяет адаптировать аналитические решения под конкретные потребности организации и обеспечивает более эффективный анализ данных.
Важно отметить, что кубы данных играют ключевую роль в процессе принятия стратегических решений в современном бизнесе. Они облегчают извлечение значимых сведений из больших объемов данных, хранящихся в реляционных базах данных, и обеспечивают быстрый доступ к этой информации для бизнес-пользователей.
Таким образом, кубы данных становятся неотъемлемой частью инфраструктуры аналитики данных, обеспечивая компаниям конкурентное преимущество и помогая им принимать обоснованные стратегические решения.
Кубы данных в реляционных БД
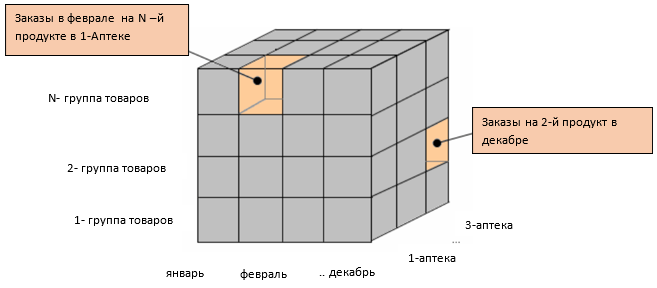
Давайте рассмотрим пример работы с кубами данных в контексте реляционных баз данных. Представим таблицу с данными о продажах, разбитых по регионам, магазинам и продуктам.
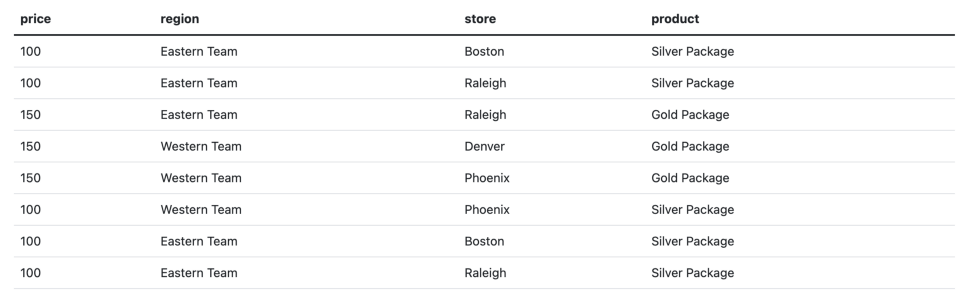
Чтобы создать куб данных из этого датасета, нужно сгруппировать сумму цен по каждой возможной комбинации разрезов. В базах данных PostgreSQL и MS SQL для этого можно использовать инструкцию GROUP BY с функцией CUBE. Например:
SELECT SUM(price) as total_sales,
region,
store,
product
FROM sales
GROUP BY CUBE(region, store, product);
Поскольку в этом примере у нас три различных разреза (регион, магазин, продукт), этот запрос создаст восемь группированных множеств и 29 строк данных (для каждой уникальной комбинации значений разрезов).
Общее количество сгруппированных множеств в кубе данных можно рассчитать с помощью формулы: 2^количество измерений. В случае нашего примера:
(region, store, product),
(region, store),
(region, product),
(store, product),
(region),
(store),
(product),
()
Этот куб данных не представляет ничего чрезмерно сложного: мы просто агрегировали данные по всем возможным сочетаниям разрезов. Ранее, чтобы передать аналитикам общее представление о продажах, инженеры данных создавали подобные таблицы.
История появления
Давайте вернёмся немного в прошлое и рассмотрим, как появились OLAP-системы и почему они были созданы. В настоящее время, так же как и в 1970-х годах, бизнес-аналитика продолжает служить одной и той же цели: заинтересованные стороны обращаются к данным и агрегируют результаты по различным критериям. Однако десятилетия назад для выполнения этих запросов использовались только интерфейсы SQL рабочих баз данных, которые поддерживали цифровые бизнес-транзакции.
На тот момент компьютеры работали очень медленно по современным стандартам. Анализ данных непосредственно в рабочих базах данных занимал много времени и требовал значительных вычислительных ресурсов. Более того, это могло мешать выполнению повседневных операций, для которых базы данных изначально и создавались.
Чтобы решить эту проблему, разработчики ПО начали создавать отдельные хранилища данных для анализа. Эти специализированные OLAP-системы хранили многомерную информацию в предварительно агрегированном виде, создавая так называемые OLAP-кубы.
Со временем эти OLAP-системы стали полноценными приложениями, которые аналитики и заинтересованные стороны могли использовать для изучения данных. С их помощью можно было выполнять такие функции, как сворачивание (Roll up), разворачивание (Drill Down), выборка и анализ (Slice and Dice) и перестановка (Pivot) данных.
С появлением кубов данных и OLAP-систем в области бизнес-аналитики технологический ландшафт претерпел значительные изменения. Эффективность обработки данных резко возросла, а с появлением облачных платформ, таких как AWS, GCP и VK Cloud, доступ к аналитическим инструментам стал ещё более доступным и экономически выгодным. Кроме того, колоночные хранилища данных значительно упростили доступ к большим объёмам информации при обычных нагрузках.
Классификация кубов данных
Кубы данных в области OLAP (Online Analytical Processing) могут быть классифицированы по различным параметрам. Один из ключевых параметров — это тип хранилища данных, используемый для их хранения и обработки. Существуют два основных типа кубов данных: многомерные кубы данных (MOLAP) и реляционные кубы данных (ROLAP).
Многомерный куб данных
MOLAP представляет собой формат хранения данных, при котором как детализированные, так и агрегированные данные хранятся в многомерных кубах. Этот формат характеризуется высокой скоростью выполнения запросов благодаря оптимизации для многомерных аналитических запросов.
MOLAP обеспечивает эффективное выполнение запросов, поскольку данные хранятся в специализированных многомерных структурах на OLAP-сервере. При выборе этого формата данных, пользователи могут работать с OLAP-кубами, осуществляя запросы с использованием специального синтаксиса или графического интерфейса.
Преимущества MOLAP включают в себя отличное быстродействие выполнения запросов и высокую эффективность индексации данных. Однако этот формат может быть неэффективен для больших объемов данных из-за низкого использования дискового пространства, особенно при работе с разреженными данными.
Реляционный куб данных
В отличие от MOLAP, в реляционных кубах данных данные, переданные в OLAP-кубы вместе с агрегатами данных, хранятся в реляционных таблицах. Этот подход широко применяется в крупных корпорациях, где размеры хранилищ данных могут быть значительными.
ROLAP имеет ряд преимуществ, включая возможность анализа данных напрямую в корпоративных хранилищах данных без необходимости копирования данных. Этот формат также обеспечивает высокий уровень защиты данных и хорошие возможности разграничения прав доступа.
Однако, в сравнении с MOLAP, ROLAP обычно имеет более низкую производительность. Для достижения сопоставимой производительности с многомерными базами данных, необходимо использовать оптимизированные схемы хранения данных.
Операции с кубами данных
В этом разделе мы рассмотрим различные операции, которые могут быть выполнены с кубами данных, от простых операций срезания и нарезки до более сложных операций детализации и поворота, позволяющих извлечь ценные инсайты из накопленных данных.
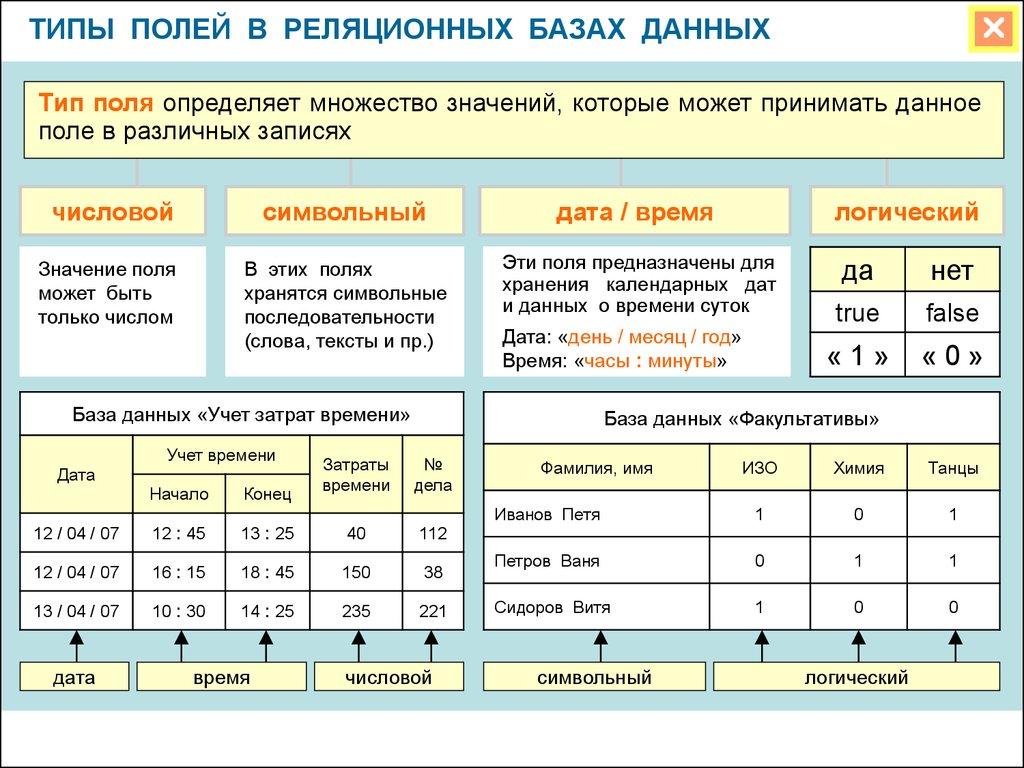
Свертка
Свертка, также известная как «консолидация» или «свертывание», представляет собой процесс суммирования всех доступных данных по одному или нескольким измерениям. Обычно для этого используются математические формулы. Например, в рамках OLAP анализа, рассмотрим розничную сеть с магазинами в разных городах. Чтобы выявить общие тенденции продаж и прогнозировать будущие показатели, данные из всех магазинов «свертываются» или консолидируются в центральном отделе продаж компании для дальнейшего анализа и расчетов.
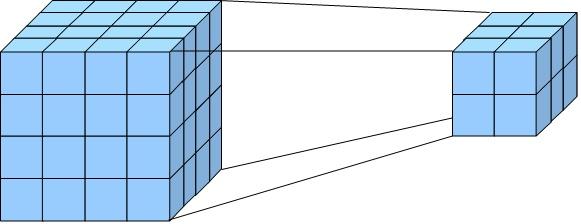
Детализация
Детализация в контексте кубов OLAP представляет собой процесс анализа данных на более низком уровне уплотнения. При детализации данные становятся более подробными, что позволяет пользователям рассматривать информацию на различных уровнях иерархии. С каждой операцией детализации уровень детальности данных увеличивается, что позволяет пользователям переходить от обобщенной информации к данным с более узким фокусом.
Например, при детализации пользователь может начать с просмотра демографической информации о населении США, затем перейти к данным по штату Вашингтон, далее к муниципальному району Сиэтл, городу Редмонд и, наконец, к штаб-квартире Майкрософт. Такой подход позволяет более глубоко изучить данные и получить дополнительные инсайты.
Когда пользователи детализируют данные, они стремятся просмотреть все отдельные транзакции или записи, которые составляют агрегированные данные куба OLAP. Суть в том, чтобы извлечь данные на самом низком уровне детализации для определенного значения меры. Например, если рассматриваются данные о продажах за определенный месяц и категорию продукта, пользователь может детализировать эти данные, чтобы увидеть каждую отдельную транзакцию или строку таблицы, входящую в эту ячейку данных.
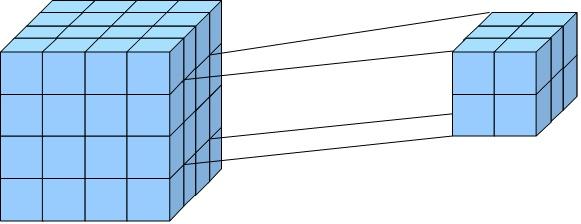
Важно различать термины «детализация» и «детализация drill-through». В отличие от детализации, детализация drill-through позволяет пользователям перейти на самый низкий уровень детализации и извлечь набор строк данных, составляющих одну ячейку агрегата, например, с помощью перехода к источнику данных.
Нарезка
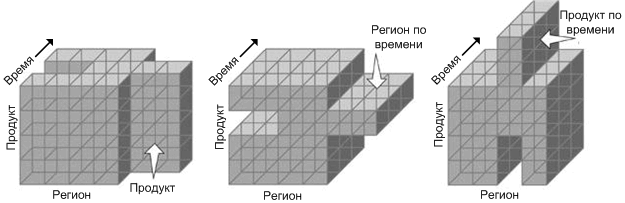
Нарезка, известная также как «слайсинг», является одной из важных операций в обработке данных в контексте кубов OLAP. Она представляет собой процесс формирования двумерного представления данных из многомерного куба OLAP. Для лучшего понимания этого процесса давайте рассмотрим пример с использованием куба MOLAP. Предположим, у нас есть данные о продажах, которые организованы по продуктам, городам и месяцам. Путем нарезки данных мы можем создать таблицу, которая покажет продукты и города за определенный месяц, представленную в виде электронной таблицы.
Этот процесс нарезки данных имеет ключевое значение для анализа и визуализации информации в удобной форме. Он позволяет сфокусироваться на конкретном срезе данных, делая их более доступными и понятными для аналитики и принятия решений. Благодаря нарезке, пользователи могут выделять определенные аспекты данных для дальнейшего изучения или отслеживания тенденций, что помогает в выявлении ключевых инсайтов и принятии более обоснованных решений.
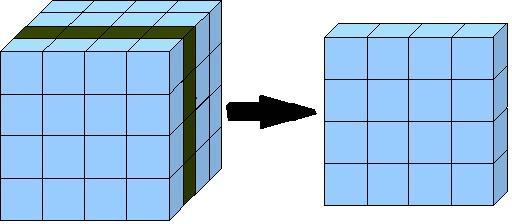
Нарезка на кубики
Нарезка на кубики, также известная как «кубирование», — это процесс, при котором специалисты по обработке данных создают более маленький куб данных из большого многомерного куба OLAP. Они делают это, определяя нужные измерения и аспекты данных и строя куб данных меньшего размера на основе исходного гиперкуба.
Для понимания этого процесса можно представить себе многомерный куб OLAP, который содержит данные о различных измерениях, таких как продукты, временные периоды и местоположения. Например, куб может содержать информацию о продажах продуктов по месяцам и регионам. При нарезке на кубики инженеры могут выбрать только определенные измерения, например, продукты и месяцы, и построить новый куб данных, который будет содержать только эту информацию.
Такой подход к нарезке на кубики позволяет сфокусироваться на конкретных аспектах данных и уменьшить объем информации для анализа. Это может быть полезно, если необходимо провести более глубокий анализ конкретных аспектов данных или если есть ограничения на доступные ресурсы для обработки и хранения больших объемов данных.
Pivot
Поворот, или «Pivot», в контексте аналитики данных, представляет собой процесс изменения структуры данных путем поворота осей. Это позволяет изменить представление информации, переставляя данные в таблице таким образом, чтобы столбцы стали строками, а строки — столбцами.
Для лучшего понимания можно представить себе обычную таблицу данных, где строки представляют собой различные категории или измерения, а столбцы — значения этих категорий или измерений. При использовании операции поворота осей данные переставляются так, что ранее столбцы становятся строками, а строки — столбцами.
Например, представим таблицу с данными о продажах, где строки представляют товары, а столбцы — даты продаж и объемы продаж для каждого товара. После операции поворота осей столбцы, содержащие даты продаж, станут строками, а строки с объемами продаж для каждого товара станут столбцами. Таким образом, мы можем лучше визуализировать и анализировать данные, увидев, какие товары продавались в определенные даты.
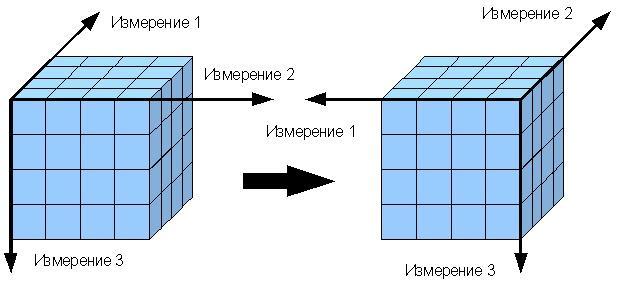
Операция поворота осей позволяет легко изменять представление данных, делая их более удобными для анализа и визуализации. Это важный инструмент в аналитике данных, который помогает сделать выводы и принимать решения на основе больших объемов информации.
Преимущества кубов данных
Кубы данных играют ключевую роль в аналитическом процессе, обеспечивая удобство, эффективность и достоверность при анализе информации.
Преимущества кубов данных включают в себя:
- Единое место хранения данных. Куб представляет собой централизованное хранилище, где содержатся все связанные данные, готовые для анализа. Это обеспечивает удобство доступа к данным и снижает необходимость обращения к различным источникам.
- Простота использования и восприятия данных. Кубы данных предоставляют простой и интуитивно понятный способ представления аналитических данных. Это упрощает процесс анализа и восприятия информации для пользователей.
- Полнота аналитических данных. Кубы данных содержат все необходимые данные для проведения анализа, что позволяет получать полную картину и принимать обоснованные решения на основе фактических данных.
- Легкая настройка отчетов без программиста. Пользователи могут легко настраивать отчеты и аналитические запросы без необходимости обращения к программистам благодаря удобным интерфейсам и инструментам для работы с кубами данных.
- Возможность детализировать отчет в процессе анализа данных. Пользователи могут детализировать отчеты, переходя от обобщенной информации к более детальным данным, что позволяет получать более глубокие инсайты и анализировать информацию на разных уровнях.
- Более быстрое формирование отчетов. Кубы данных позволяют формировать отчеты значительно быстрее по сравнению с традиционными методами анализа данных, что сокращает время на подготовку информации для принятия решений.
- Непротиворечивость данных в отчетах. Благодаря централизованному хранению данных и использованию единого источника информации, отчеты на основе кубов данных обладают высокой непротиворечивостью и достоверностью.
- Консолидация информации из разных баз данных. Кубы данных позволяют объединять информацию из различных источников данных, что облегчает сравнение и анализ данных из разных источников.
- Повышенная защита данных. Кубы данных обеспечивают повышенный уровень защиты данных благодаря возможности управления доступом и шифрованию информации, что обеспечивает конфиденциальность и целостность данных.
- Эквивалентность одного OLAP-отчета целому набору простых отчетов. С помощью кубов данных можно создавать один высокоуровневый отчет, который эквивалентен целому набору простых отчетов, что упрощает процесс анализа и позволяет получать более глубокие инсайты из данных.
Недостатки data cube
Важно осознавать, что, несмотря на свои многочисленные преимущества, кубы данных OLAP также имеют свои ограничения и недостатки. Определение и понимание этих недостатков помогает более полно оценить их эффективность и применимость в конкретных сценариях использования.
Недостатки использования кубов данных для анализа могут включать в себя:
- Сложность реализации. Создание и настройка кубов данных может требовать определенного уровня экспертизы и времени настройки, особенно при использовании распределенных или высокооптимизированных архитектур.
- Затраты ресурсов. Внедрение и поддержка кубов данных может потребовать значительных ресурсов, включая вычислительную мощность, память и хранилище данных.
- Сложность обновления данных. Поскольку кубы данных представляют собой предварительно агрегированные структуры данных, обновление информации в них может потребовать пересчета агрегатов, что может быть ресурсозатратным процессом.
- Ограничения в анализе данных. В некоторых случаях кубы данных могут иметь ограничения на количество и типы данных, которые можно анализировать, что может усложнить выполнение некоторых видов аналитических запросов.
- Необходимость поддержки. Кубы данных требуют постоянной поддержки и обновления для обеспечения их актуальности и соответствия требованиям бизнеса. Это может включать в себя периодическое обновление структуры кубов, добавление новых измерений и мер, а также оптимизацию запросов.
Учитывая эти недостатки, важно тщательно оценить потребности и возможности вашей организации перед принятием решения о внедрении кубов данных.
Выводы
В конечном итоге, использование кубов данных OLAP демонстрирует значительные преимущества в сфере аналитики и принятия решений. Эти многомерные структуры данных позволяют эффективно организовывать, агрегировать и анализировать большие объемы информации, что делает процесс принятия решений более обоснованным и эффективным. Благодаря возможности быстрого выполнения сложных запросов и операций агрегирования, кубы данных OLAP становятся важным инструментом для бизнес-аналитики и стратегического планирования.
Кроме того, гибкость и удобство использования кубов данных OLAP делают их доступными для широкого круга пользователей, включая как специалистов в области аналитики и информационных технологий, так и конечных пользователей из различных отраслей и сфер бизнеса. Возможность проводить анализ данных на разных уровнях иерархии, а также быстро изменять представление данных в соответствии с потребностями пользователей, делает кубы данных OLAP востребованными и эффективными инструментами в современном бизнесе.
Таким образом, кубы данных OLAP представляют собой не только средство для хранения и анализа информации, но и ключевой компонент для принятия обоснованных стратегических решений. Их использование способствует повышению производительности бизнес-процессов, улучшению качества принимаемых решений и обеспечивает конкурентное преимущество компании на рынке.