


В современном мире огромное количество информации пересекается и обрабатывается каждую секунду. Для обеспечения надежной передачи и обработки этой информации между приложениями и компонентами систем необходимы эффективные и масштабируемые средства. Однако, с ростом объемов данных и увеличением сложности систем, становится сложно справляться с этими задачами средствами традиционных архитектур.
Именно в таком контексте приходит на помощь Apache Kafka — мощная и гибкая распределенная система обмена сообщениями. В этой статье мы рассмотрим архитектуру и ключевые особенности Apache Kafka, исследуем области ее применения и рассмотрим преимущества, которые она приносит в мире обработки данных и обмена данными.
Общие сведения
Распределенные системы обычно включают в себя несколько сервисов. Некоторые из них генерируют различные события, такие как метрики, логи, данные мониторинга и другие. Другие сервисы нуждаются в получении этих данных. Kafka можно охарактеризовать как гибрид между распределенной базой данных и системой обмена сообщениями, способной масштабироваться горизонтально.
Она собирает данные от приложений, сохраняет их в своем распределенном хранилище, группируя по тематическим категориям, и предоставляет их компонентам приложения на основе подписки. Сами сообщения хранятся на различных узлах-брокерах, обеспечивая высокую доступность и надежность системы.
Топик представляет собой способ организации потоков сообщений по категориям в хранилище. Сервисы отправляют сообщения в определенный топик, а затем потребители подписываются на этот топик и читают их из него. Для каждого топика в Apache “Кафка” существует лог сообщений, который может быть разделен на несколько частей. Разделы представляют собой последовательность данными в топике в порядке их поступления.
Сообщения сохраняются в журнале — долговременной упорядоченной структуре данных. Записи в журнал можно только добавлять, их нельзя изменять или удалять, и информация читается слева направо, обеспечивая правильный порядок элементов.
Apache Kafka не является чистой системой управления базами данных, хотя она обеспечивает атомарность, согласованность, изолированность и долговечность данных, а также предоставляет возможность выборочного доступа к данным с помощью KSQL — SQL-движка, основанного на API Kafka Streams. Платформу используют как журнал фиксации событий и интеграционный центр для множества внешних систем управления базами данных и хранилищ данных.
Область применения
Kafka находит широкое применение в различных областях, где требуется централизованный сбор, обработка, безопасное хранение и передача большого объема данных от разных сервисов и источников.
Ниже представлены некоторые области, в которых “Кафка” активно используется:
- Интернет вещей (IoT) и промышленный интернет вещей (IIoT). Kafka применяется в системах с множеством датчиков, сенсоров и контроллеров, где требуется обработка большого объема данных с различных конечных устройств.
- Телекоммуникационные операторы. Крупные операторы, такие как ВымпелКом, МТС и Ростелеком, используют Kafka для обработки и передачи данных о телефонных звонках и сообщениях.
- Системы геопозиционирования. Foursquare использует “Кафка” для передачи данных между онлайн и офлайн системами, а также для интеграции средств мониторинга в свою инфраструктуру на базе Hadoop.
- Финансовые системы. Финансовые организации, включая Сбербанк, Тинькофф, Альфа-Банк и ING Bank, используют Kafka для обработки и передачи финансовых данных и событий.
- Онлайн-игры. Компании, такие как Demonware (подразделение Activision Blizzard), используют “Кафка” для обработки логов пользователей и событий в онлайн-играх.
- Аналитические системы. Компании, такие как IBM и DataSift, используют Kafka для сбора и мониторинга событий в реальном времени, а также для отслеживания данных, потребляемых пользователями.
- Социальные сети. Twitter использует Kafka для обработки потоков данных, а LinkedIn использует его для передачи данных о деятельности пользователей и мониторинга приложений.
В простейшем случае, “Кафка” позволяет собирать логи сессий клиентов или логи с серверов в режиме реального времени и сохранять их в центральном месте, например, в файловой системе Apache Hadoop (HDFS).
Кроме того, Kafka может быть использован для построения конвейера данных, позволяя извлекать ценную информацию для бизнеса с использованием алгоритмов машинного обучения из сырых данных.
Принцип работы
Представьте себе систему, в которой некоторые участники создают и отправляют сообщения, а другие получают их. В Apache “Кафка” те, кто создает и передает их, называются издателями (producer), а те, кто их получает, называются подписчиками (consumer).
Для объединения издателей и подписчиков Kafka создает отдельные каналы, которые называются темами (topics). Издатели отправляют сообщения в конкретные темы, а подписчики следят за определенными темами. Как только в теме появляется новое сообщение, его получают все подписанные на нее адресаты.
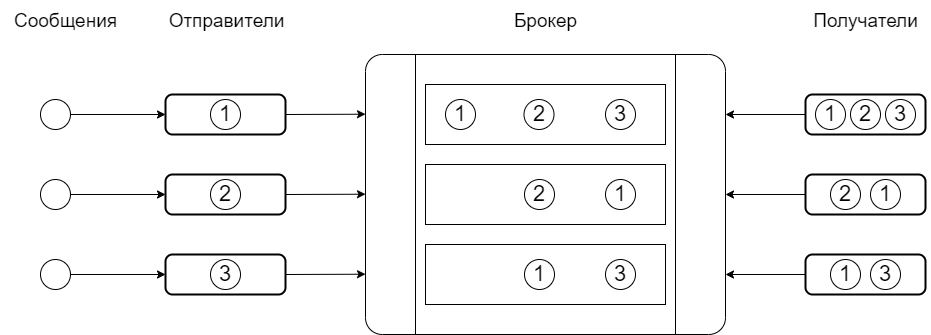
Внутри тем существуют разделы (partitions), каждый из которых предназначен для конкретного подписчика. Одно и то же сообщение может попасть в одну тему, но в разные разделы, и его могут прочитать несколько подписчиков.
Поскольку сообщений может быть много, они добавляются в последовательную очередь, из которой подписчик считывает их в порядке их поступления. Даже при такой последовательной обработке “Кафка” способна обрабатывать миллионы сообщений в секунду.
Чтобы уменьшить риск потери сообщений при больших объемах данных, Kafka дублирует разделы, создавая «лидера» и несколько «подчиненных». Лидер работает с издателями и подписчиками, а подчиненные просто сохраняют копии данных, которые находятся на лидере, и служат репликами. Это обеспечивает сохранность данных даже в случае сбоя лидера и позволяет системе продолжать работу.
Если основной раздел выходит из строя, реплика автоматически берет на себя его функции и продолжает принимать и доставлять сообщения.
Давайте рассмотрим пример работы брокера данных Apache “Кафка” в интернет-магазине, где есть сервисы для поиска товаров, оформления заказов и отправки уведомлений клиентам, связанные с Kafka.
- Когда в системе появляется новый товар, сервис отправки уведомлений об этом обращается к Apache “Кафка” и отправляет сообщение в тему «Новые товары». Сервисы оформления заказов и поиска товаров подписаны на эту тему и моментально получают информацию о новом товаре.
- Когда клиент совершает покупку, сервис оформления заказов отправляет сообщение в тему «Новые заказы». Все подписанные на эту тему сервисы получают уведомление о новом заказе.
- Этот обмен происходит в режиме реального времени. Сервисы постоянно следят за нужными темами и мгновенно получают информацию из них. Таким образом, если товар заканчивается, Kafka немедленно уведомляет об этом.
Это лишь упрощенная схема использования Apache “Кафка” для обмена данными в реальном времени в интернет-магазине, и она демонстрирует эффективность Kafka в обработке сообщений и событий между сервисами.
Особенности и архитектура
Архитектура и принцип работы Apache Kafka можно кратко описать следующим образом:
- Распределенность. Система “Кафка” развернута на нескольких аппаратных платформах (кластерах), что обеспечивает ей высокую отказоустойчивость. Это означает, что у нее есть несколько узлов, которые работают вместе.
- Масштабируемость. К Kafka можно просто добавлять новые узлы (брокеры сообщений), чтобы увеличить ее производительность и масштабируемость. Это позволяет системе обрабатывать большие объемы данных.
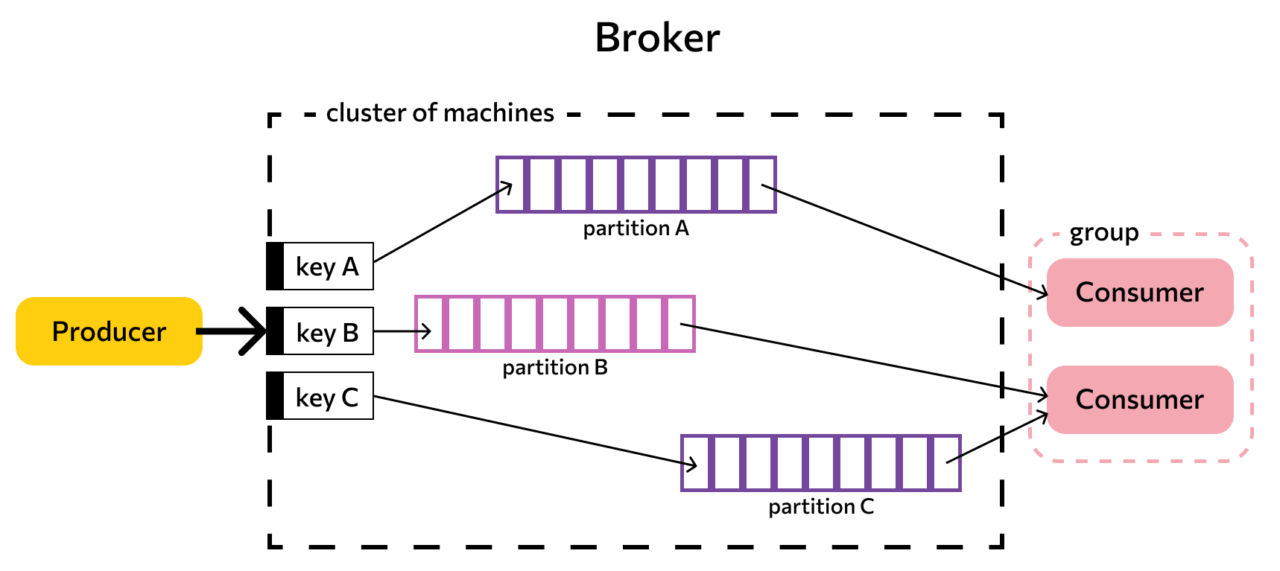
В архитектуре Kafka Apache ключевыми компонентами являются:
- Топик (тема). Это виртуальное хранилище сообщений с однородным или похожим содержанием, из которого потребители извлекают нужную информацию.
- Потребитель (consumer). Это приложение или процесс, который принимает данные, сгенерированные продюсером.
- Продюсер (producer). Это приложение или процесс, который создает и отправляет данные (генерирует сообщения).
- Сообщение. Это набор данных, который выполняет какое-либо действие или содержит информацию (например, авторизацию, заказ или подписку).
- Брокер (broker). Это узел или диспетчер, который передает сообщения от продюсера к потребителю. Он играет роль посредника.
Процесс работы Apache “Кафка” можно упростить следующим образом:
- Продюсер создает сообщение и отправляет его на сервер Kafka.
- Брокер Kafka сохраняет сообщение в соответствующем топике, на который подписаны потребители.
- Потребитель может запросить данные из топика и получить нужную информацию.
Сообщения хранятся в Kafka как записи в журнале, расположенные в строгой последовательности. Их можно только добавлять, а не изменять или удалять. Данные сохраняются в порядке их поступления и читаются слева направо. Брокеры “Кафка” не обрабатывают записи, а только помещают их в соответствующий топик в кластере. Хранение сообщений может продолжаться определенное время или до достижения определенного порога.
Если объем данных в топике слишком большой, Kafka может разделять его на секции, каждая из которых содержит сообщения с общим признаком. Например, запросы пользователей могут быть сгруппированы по первой букве их имени. Это позволяет потребителям извлекать только интересующие их данные, ускоряя процесс обмена данными.
Преимущества
В этом разделе собраны наиболее очевидные сильные стороны этого сервиса. Давайте рассмотрим каждый из них более подробно.
Отказоустойчивость
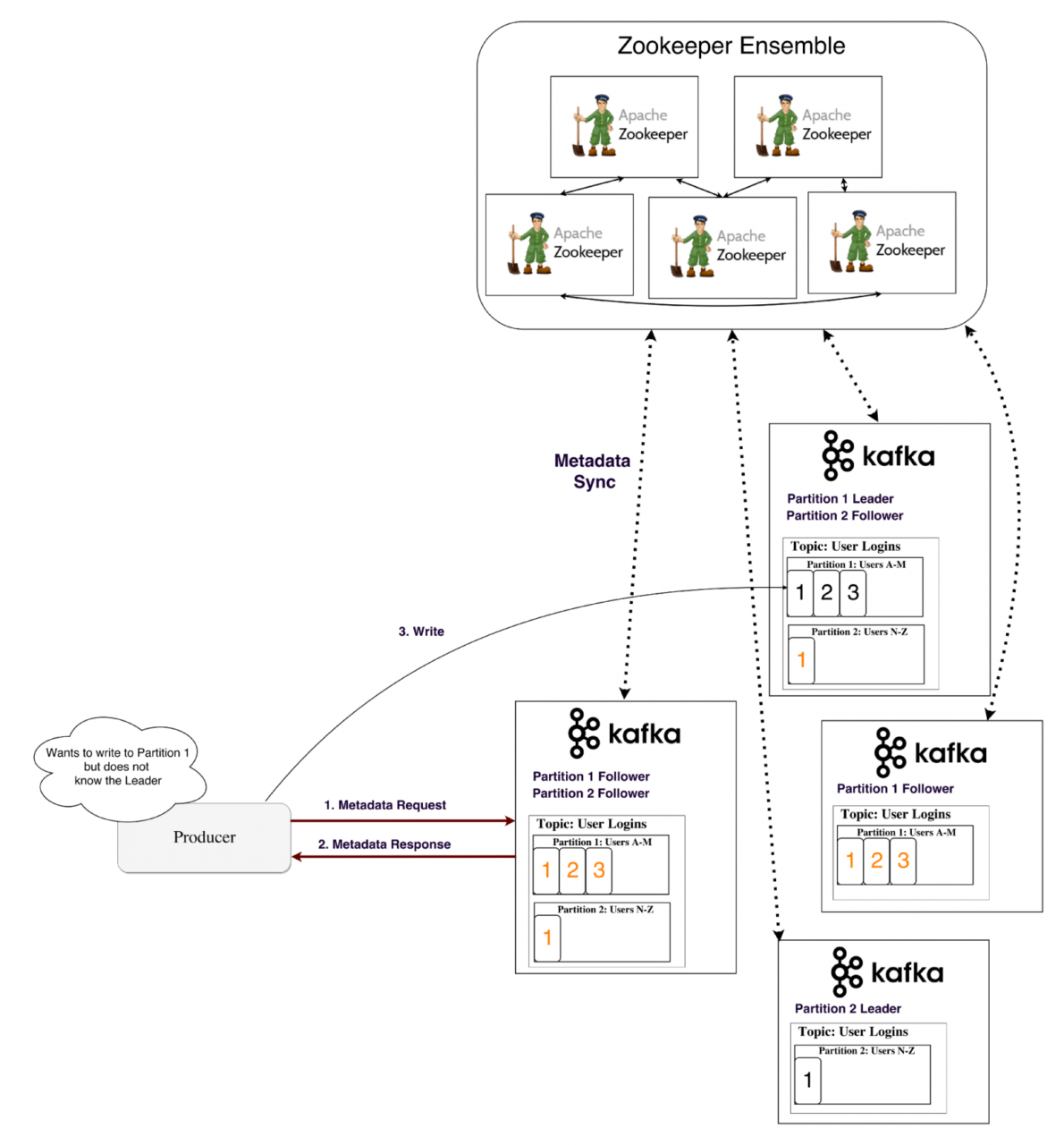
Отказоустойчивость в Kafka обеспечивается ее распределенной архитектурой и механизмом репликации данных. В данной системе узлы размещены на нескольких кластерах, что предоставляет высокую степень надежности.
Когда продюсер отправляет сообщение, “Кафка” создает его копии и хранит их на различных узлах. Один из брокеров становится «ведомым» для определенной секции данных, и через него потребители получают доступ к данным. Другие брокеры остаются ведомыми и занимаются сохранностью сообщений (их копий), даже если один или несколько узлов выходят из строя.
Таким образом, распределенная природа Kafka и репликация записей обеспечивают высокую устойчивость системы. Кроме того, интеграция с Apache ZooKeeper способствует координации компонентов системы, что усиливает ее надежность и отказоустойчивость.
Масштабируемость
Apache Kafka обладает возможностью «горячего» расширения, что означает, что ее масштабирование происходит путем добавления новых серверов в кластер без выключения всей системы. Это позволяет избежать простоев, связанных с необходимостью обновления аппаратного оборудования серверов.
Этот принцип масштабирования напоминает горизонтальное масштабирование, где на существующую серверную машину можно добавить дополнительные ресурсы, такие как жесткие диски, процессоры, оперативная память и так далее.
И если потребуется уменьшить систему, лишние серверы можно легко исключить из кластера.
Производительность
В Apache Kafka процессы создания и отправки сообщений, а также их чтения организованы независимо друг от друга. Это означает, что множество приложений и процессов могут одновременно и параллельно выполнять роли как производителей, так и потребителей сообщений. Совместно с распределенной архитектурой и возможностью масштабирования, это делает “Кафка” универсальным инструментом как для небольших, так и для крупных проектов с большими объемами данных.
Открытый исходный код
Kafka Apache является проектом с открытым исходным кодом, и это приносит несколько значимых преимуществ:
- Обширная документация и сообщество. Благодаря свободной лицензии от Apache Software Foundation, “Кафка” имеет обширное сообщество разработчиков и пользователей. Это означает наличие обширной справочной информации, мануалов, советов и обзоров, предоставляемых как официальными разработчиками, так и сторонними энтузиастами и профессионалами.
- Расширяемость. Благодаря открытому исходному коду, существует множество дополнительных программных пакетов и патчей, созданных сторонними разработчиками. Эти расширения могут улучшить и расширить базовые возможности Kafka, позволяя пользователям настроить систему под свои конкретные потребности.
- Гибкость настроек. Открытый исходный код также предоставляет возможность адаптировать “Кафка” под уникальные требования и специфику конкретного проекта. Это означает, что пользователи могут настраивать систему в соответствии с конкретными задачами, что делает ее гибкой и масштабируемой.
Безопасность
Apache Kafka обеспечивает безопасность и целостность данных с помощью различных инструментов. Например, можно настроить уровень изоляции для транзакций, что позволяет предотвратить чтение незавершенных или отмененных сообщений.
Кроме того, благодаря сохранению данных в топиках, пользователь имеет возможность отслеживать изменения в системе в любой момент. И применение принципа последовательной записи ускоряет поиск нужных сообщений.
Все это способствует обеспечению безопасной работы и надежности данных в “Кафка”.
Долговечность
В Kafka данные сохраняются в долгосрочных виртуальных хранилищах в течение определенного временного периода, который может составлять дни, недели или месяцы.
Благодаря распределенному хранению информации, она остается доступной даже при сбое одного или нескольких узлов. Это означает, что потребитель данных может в любой момент обратиться к необходимому сообщению в топике, определив его положение или смещение, и не беспокоиться о потере данных из-за сбоев в системе.
Интегрируемость
Интеграция — это одно из сильных преимуществ Apache Kafka. Кafka использует собственный протокол на базе TCP для взаимодействия, что позволяет ей взаимодействовать с различными протоколами передачи данных, такими как REST, HTTP, XMPP, STOMP, AMQP, MQTT.
Также в Kafka есть встроенный фреймворк “Кафка” Connect, который облегчает подключение Kafka к различным источникам данных, включая базы данных, файловые системы и облачные хранилища. Это делает “Кафка” очень гибкой и способной к интеграции с другими системами и источниками данных.
Отличия Kafka от RabbitMQ
Сравнение между “Кафка” и RabbitMQ часто производится, так как обе системы предназначены для обмена информацией между приложениями и работают в режиме «издатель — подписчик», а также обеспечивают репликацию сообщений. Тем не менее, они имеют фундаментальные различия в моделях доставки сообщений.
Kafka использует модель «pull», где получатели сами извлекают сообщения из топиков. С другой стороны, RabbitMQ использует модель «push» и активно отправляет сообщения получателям.
Еще одно важное различие заключается в обработке сообщений: RabbitMQ удаляет сообщения после их доставки, в то время как Kafka хранит их до предварительно заданной очистки журнала. Это позволяет “Кафка” сохранять текущее и предыдущие состояния системы, что полезно, например, для истории данных. Множество потребителей может читать одни и те же данные независимо, что удобно в event-driven системах.
RabbitMQ обладает гибким управлением очередями сообщений, но при высокой нагрузке может снижаться производительность. Поэтому Kafka лучше подходит для сбора и агрегации событий из разных источников, метрик и логов, в то время как RabbitMQ хорошо подходит для быстрого обмена сообщениями между несколькими сервисами.
Недостатки
Основным ограничением системы является ее ориентированность на обработку больших объемов данных. В связи с этим, функциональность маршрутизации потоков ограничена по сравнению с другими аналогичными платформами. Тем не менее, с развитием Kafka, это ограничение становится менее заметным, а сама система становится более гибкой и универсальной.
Заключение
В заключение, Apache “Кафка” представляет собой мощную и гибкую распределенную систему обмена сообщениями, которая нашла широкое применение в различных областях. Ее распределенная архитектура, масштабируемость и высокая отказоустойчивость делают ее идеальным выбором для обработки больших объемов данных и обеспечения надежного обмена сообщениями между различными компонентами приложений.
Apache Kafka обладает рядом преимуществ, таких как открытый исходный код, высокая производительность, поддержка множества протоколов передачи данных, а также интеграция с различными хранилищами данных. Ее способность обеспечивать безопасность, долговечность и интегрируемость делают ее незаменимым инструментом в современных приложениях и системах обработки данных.
Несмотря на некоторые ограничения в функционале маршрутизации потоков данных, Apache “Кафка” продолжает развиваться, становясь более гибкой и универсальной. Она остается важным компонентом для сбора, обработки и передачи данных в реальном времени, и ее роль в современных высоконагруженных системах трудно переоценить.





