


В мире современных данных собирать и анализировать информацию во времени — неотъемлемая часть множества приложений и проектов. От мониторинга IoT-устройств до анализа финансовых рынков, отслеживания изменений в сетях до создания отчетов — временные ряды охватывают широкий спектр сценариев использования.
В этой статье мы погрузимся в мир TimescaleDB — мощной временнóй рядовой базы данных, построенной на основе PostgreSQL. Рассмотрим его архитектуру, функциональные возможности и производительность, а также узнаем, как TimescaleDB может облегчить управление данными времени в ваших проектах.

Общие сведения
Проект TimescaleDB представляет собой расширение для PostgreSQL, распространяемое под лицензией Apache 2.0. Он также содержит часть кода с расширенными функциями, доступными по отдельной частной лицензии Timescale (TSL). Эта лицензия ограничивает возможность внесения изменений в код, запрещает его использование в сторонних продуктах и не позволяет бесплатное использование в облачных БД.
Одной из интересных особенностей TimescaleDB является возможность использования полных SQL-запросов для анализа накопленных данных. Это сочетает в себе простоту использования, характерную для реляционных СУБД, с масштабируемостью и функциональностью, характерными для специализированных NoSQL-систем.
Структура хранения данных в TimescaleDB оптимизирована для обеспечения высокой скорости агрегации данных. Она поддерживает пакетную агрегацию данных с использованием индексов, хранящихся в оперативной памяти, и загружает исторические сегменты данных в заднем порядке, применяя транзакции.
Ключевой особенностью TimescaleDB является поддержка автоматического разделения массива данных. Входящий поток данных автоматически распределяется между секционированными таблицами.
Секции могут быть созданы на основе времени (с данными за определенный период времени) или по произвольному ключу (например, идентификатору устройства, местоположению и т. д.). Секционированные таблицы могут быть распределены по разным дискам для оптимизации производительности.
Для запросов многораздельная БД выглядит как большая таблица, называемая гипертаблицей. Гипертаблица представляет собой виртуальное представление множества отдельных таблиц, в которых накапливаются входящие данные.
Важность выбора подходящей СУБД на примере TimescaleDB
Выбор системы управления базами данных (СУБД) для проекта отличается от выбора фреймворка или оркестратора. Когда решается, например, использовать Nomad, архитектор или технический лидер, обычно (почти всегда) имеет четкое представление о целях этого решения. Он осознает, что Kubernetes может оказаться избыточным и сложным для данного проекта, и задает вопрос: «Зачем?»
Поскольку функциональность БД часто схожа, при равных архитектурных условиях разницы между различными решениями могут быть незначительными. Поэтому при работе с СУБД на первый план выходит опыт команды по работе с конкретным продуктом и его совместимость с текущей инфраструктурой. Это означает, что можно избежать необходимости создавать дополнительную логику вокруг нового кластера и вместо этого масштабировать существующее решение, которое уже используется в продакшене.
Существуют проекты, которые требуют использования нескольких разных СУБД, хотя на первый взгляд одной СУБД было бы достаточно. Однако в коммерческих проектах, где важна скорость и производительность, такой подход может быть обоснованным. Например, в сравнении с обычным PostgreSQL TimescaleDB может значительно ускорить работу с данными, улучшив ее в 2000 раз.
Среди других преимуществ TimescaleDB стоит выделить:
- Встроенный инструментарий с уже оптимизированными структурами данных для аналитических запросов «из коробки».
- Автоматическое разделение данных (партицирование).
- Встроенный механизм управления задачами.
- Возможность масштабирования на несколько узлов (мультинодность).
Область применения и принцип работы
TimescaleDB находит свое практическое применение в решениях, подобных тому, как описано выше. В этих случаях TimescaleDB интегрируется для работы с данными из AmoCRM в приложениях, предоставляя удобный интерфейс взаимодействия на основе PostgreSQL, что упрощает создание приложений и разработку бизнес-процессов на основе данных AmoCRM.
Размер кластера TimescaleDB зависит от объема данных в системе. Для среднестатистической системы требуется небольшой объем ресурсов. Например, в данном примере используется одна нода с 6 vCPU и 16 ГБ RAM при объеме данных в 90 ГБ. Несмотря на то, что кластер включает только мастер-ноду, интеграция с системой позволяет ей действовать как еще один мастер, что повышает отказоустойчивость системы.
Система записывает и синхронизирует все действия пользователей и системные события, которые обрабатываются приложением, в PostgreSQL-кластер. Внутри кластера выделяется отдельный сегмент для хранения данных временных рядов, а TimescaleDB занимается их обработкой.
Одним из ключевых преимуществ являются гипертаблицы, которые ускоряют доступ к данным, обеспечивают возможность настройки партицирования и сжатия данных, в том числе «холодных» данных. Кроме того, TimescaleDB помогает решать задачи по удалению и «утилизации» устаревших данных с помощью политики хранения данных (retention policy).
Гипертаблицы хранят данные о событиях, таких как действия с карточкой клиента, создание задачи в сделке, выполнение задачи и другие. Эти события служат триггерами для различных бизнес-процессов. Доступ к старым событиям не так часто требуется, поэтому данные можно сжимать и физически перемещать на другой диск. Это позволяет поддерживать высокую скорость записи и чтения новых данных, что может быть даже быстрее, чем при использовании обычной БД PostgreSQL.
Помимо облачной БД, система также может использовать кластер Managed Kubernetes для развертывания сервера синхронизации.
Архитектура
Архитектура TimescaleDB основана на расширении PostgreSQL, что позволяет ей функционировать как часть PostgreSQL в одном инстансе. Это означает, что TimescaleDB работает совместно с PostgreSQL и может использовать всю мощь стандартных функциональных возможностей PostgreSQL, одновременно обрабатывая бизнес-данные и данные временных рядов.
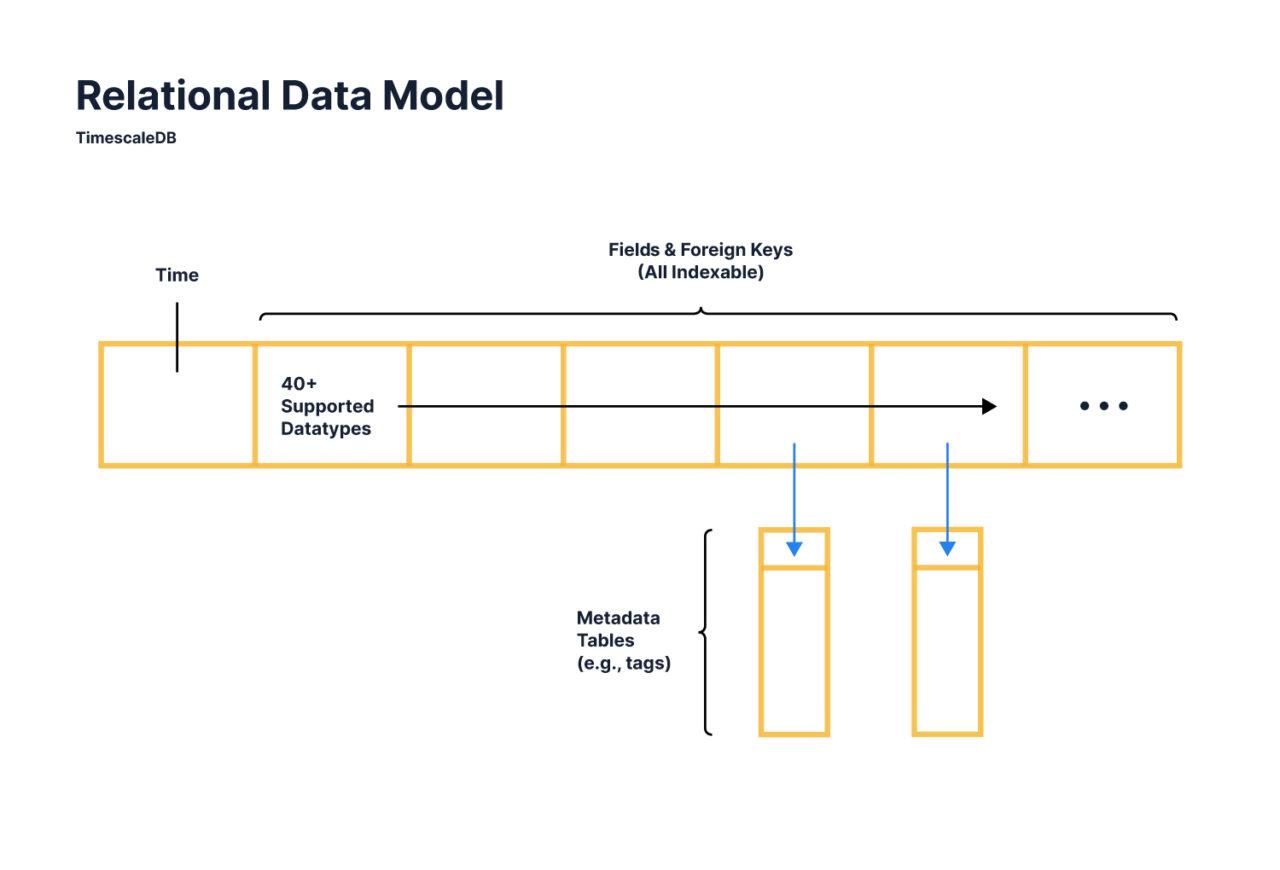
С точки зрения пользователя, TimescaleDB вводит специальный тип таблиц, известных как гипертаблицы (hypertables). Гипертаблицы, на самом деле, являются абстракцией или виртуальным представлением набора отдельных таблиц, которые содержат данные, разделенные на чанки (chunks).

Чанки, ihrerseits, представляют собой разделение гипертаблицы на одну или несколько измерительных осей. Все гипертаблицы обязательно разбиваются по времени, и также могут быть разбиты по различным ключам разделения, таким как deviceId, userId, location и т.д. Иными словами, данные разбиваются как по времени, так и по другим измерениям.
Гипертаблица
Гипертаблица (Hypertable) является ключевой точкой взаимодействия с данными в TimescaleDB и представляет собой абстракцию одной непрерывной таблицы во всех пространственных и временных измерениях. Доступ к данным в гипертаблице осуществляется с использованием стандартного SQL.
Практически все операции пользователя с TimescaleDB связаны с гипертаблицами, включая создание и изменение таблиц, вставку данных, выборку данных и другие. Каждый экземпляр TimescaleDB может содержать несколько гипертаблиц, каждая из которых может иметь собственную схему.
Создание гипертаблицы в TimescaleDB выполняется с использованием двух простых SQL-команд: CREATE TABLE (с стандартным синтаксисом SQL), за которой следует SELECT create_hypertable().

В гипертаблицах автоматически создаются индексы как по времени, так и по ключам разделения, но также можно создавать дополнительные индексы, так как TimescaleDB поддерживает полный набор типов индексов PostgreSQL.
“Чанки”
TimescaleDB использует внутреннюю структуру, называемую «чанками» (chunks), для эффективного хранения и управления данными временных рядов. Под каждую гипертаблицу автоматически создаются чанки, и каждый из них представляет собой определенный временной интервал и пространственную область.
Эти чанки не пересекаются, что позволяет оптимизировать процесс выполнения запросов, так как планировщик запросов может минимизировать количество чанков, которые необходимо обрабатывать при выполнении запроса.
Каждый чанк на самом деле представляет собой стандартную таблицу в БД, которая наследуется от родительской гипертаблицы. Это основано на концепции наследования таблиц в PostgreSQL, что позволяет эффективно управлять данными временных рядов.

Одной из важных характеристик чанков является их оптимальный размер. Это обеспечивает, что все индексы в виде B-деревьев будут находиться в оперативной памяти при вставке новых данных в гипертаблицу. Используя разумный размер чанков, можно избежать дорогостоящих операций вроде вакуумирования при удалении данных, так как можно удалять необходимые чанки целиком.
Такая структура данных TimescaleDB возникла из особенностей временных рядов, где обычно интерес представляют данные, близкие по времени. При вставке данных это обычно последние записи во времени, а при выборке — данные за определенный период.
Отличия между TimescaleDB и ClickHouse
Сравнивая TimescaleDB и ClickHouse, можно заметить, что хотя они могут быть похожи на первый взгляд, у них есть существенные архитектурные различия. Один из ключевых факторов при выборе между ними — это тип рабочей нагрузки, которую предполагается обрабатывать.
ClickHouse специализируется на работе с OLAP-нагрузками, которые по своей природе похожи на time series-данные, но ориентированы на обработку потоковых событий. Это может включать в себя обработку данных рекламных сетей или онлайн-игр.
Одной из ключевых особенностей ClickHouse является его колоночная архитектура, которая позволяет более эффективно хранить и обрабатывать данные. В отличие от строчных СУБД, где данные хранятся по строкам и для поиска нужной информации требуется полный перебор таблицы, в колоночных СУБД данные хранятся по колонкам, что позволяет быстрее получать доступ к нужным данным. Также данные можно сортировать по колонкам, что оптимизирует запросы с использованием нескольких колонок.
Колоночная архитектура ClickHouse также позволяет увеличить эффективность работы при чтении с диска, так как каждая колонка представлена как отдельный файл на диске. Это упрощает сжатие данных и обеспечивает высокую производительность благодаря более коротким запросам по сравнению со строчными СУБД.
Кроме того, ClickHouse предлагает дополнительные преимущества, такие как опция сэмплирования для быстрой проверки данных на конкретных сегментах и возможность хранения каждой колонки как отдельного файла, что упрощает управление БД.
В итоге, выбор между TimescaleDB и ClickHouse зависит от конкретных потребностей проекта и типа обрабатываемой нагрузки. Если речь идет о работе с потоковыми событиями и OLAP-запросами, то ClickHouse может быть более подходящим выбором благодаря своей колоночной архитектуре и оптимизации для таких задач.
Производительность вставки
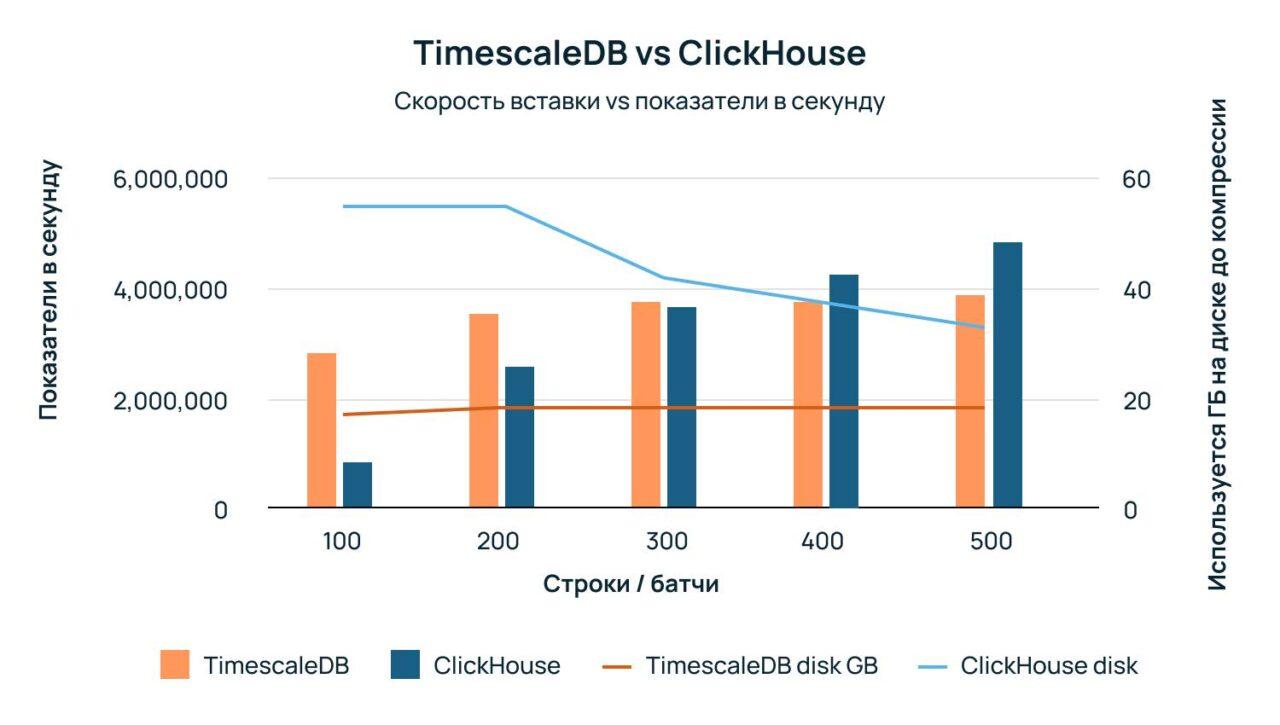
Когда речь идет о производительности вставки данных, обе БД, ClickHouse и TimescaleDB, показывают впечатляющую скорость при обработке пакетов данных в размере от 5 000 до 15 000 строк на вставку. Однако при более низком объеме пакетов результаты начинают различаться в двух аспектах: скорости вставки и потреблении дискового пространства.
ClickHouse превосходит TimescaleDB при работе с большими объемами данных в пакетах (5 000 строк/пакет), и при этом занимает менее дискового пространства, потребляя около 16 ГБ до сжатия данных.
Однако при использовании более небольших объемов данных в пакетах TimescaleDB сохраняет стабильную скорость вставки, которая даже превосходит скорость ClickHouse в диапазоне от 100 до 300 строк в пакете. В этом случае, хотя TimescaleDB продемонстрировал более высокую производительность, он также потребляет в 2,7 раза больше дискового пространства по сравнению с ClickHouse. Это различие в потреблении дискового пространства объясняется особенностями архитектурного дизайна каждой из БД.
Производительность запросов
Для оценки производительности запросов был использован стандартный набор данных, включающий запрос данных для 4 000 хостов за трехдневный период и содержащий общее количество строк, составляющее 100 миллионов записей. Такой набор данных является репрезентативным для проведения эталонных тестов, поскольку обеспечивает достаточное количество строк и разнообразие данных для выполнения множества циклов ввода и запросов к БД в течение нескольких часов.
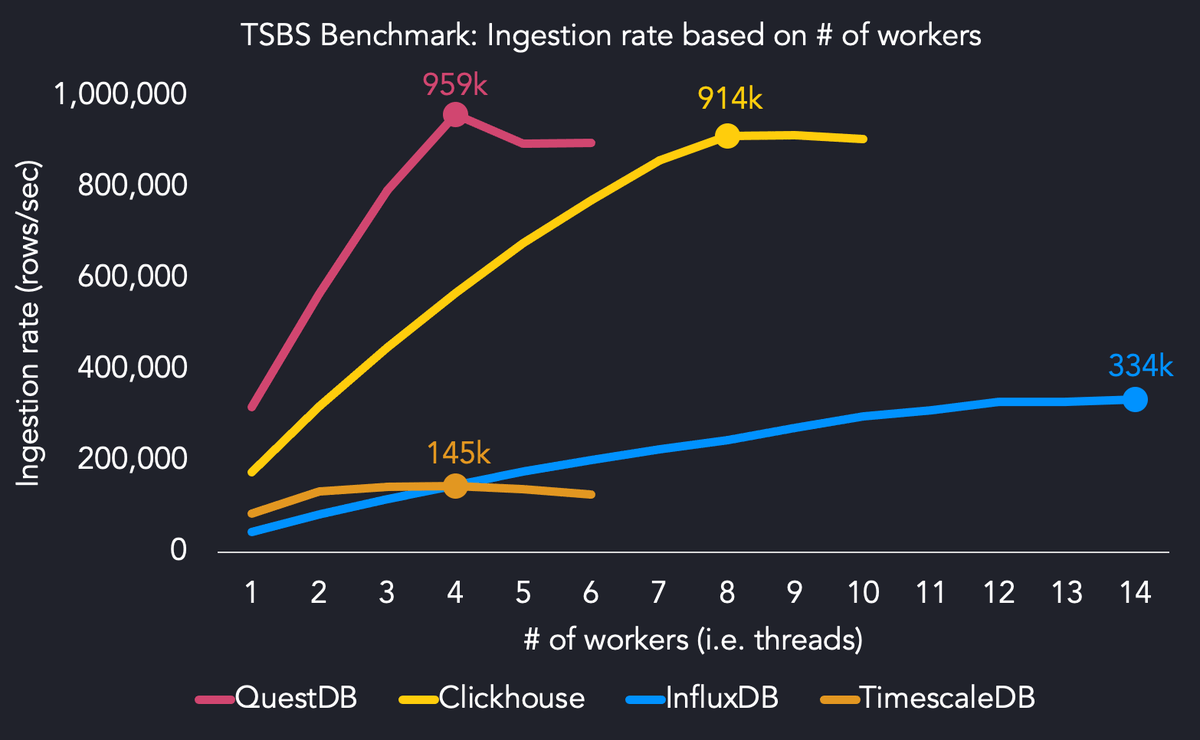
Исходя из известной репутации ClickHouse как быстрой OLAP-базы данных, ожидалось, что она будет превосходить TimescaleDB в большинстве запросов в бенчмарке.
В первоначальных тестах без сжатия данных TimescaleDB и ClickHouse показали схожие результаты. Однако, когда было включено сжатие данных в TimescaleDB, что является рекомендуемой практикой, произошел обратный эффект: TimescaleDB начала превосходить ClickHouse практически во всех типах запросов.
Отличия между TimescaleDB и QuestDB
Сравнивая TimescaleDB и QuestDB, стоит отметить, что QuestDB мог бы быть заменен InfluxDB или OpenTSDB, так как важно провести сравнение TimescaleDB с другой БД, которая имеет схожий тип нагрузки.
Обе эти БД, включая TimescaleDB, ориентированы на работу с данными временных рядов и активно применяются в различных областях, таких как блокчейн, аналитика, онлайн-игры и интернет вещей.
QuestDB, с одной стороны, имеет свою «специализацию» в секторе финансовых технологий и торговых платформ, где скорость обработки данных играет ключевую роль и даже миллисекунды имеют значение. Это обусловлено высокой конкуренцией и необходимостью обрабатывать данные максимально быстро. Одной из основных причин выбора QuestDB для этой области может быть наличие качественной документации и высокой производительности.
С другой стороны, QuestDB также часто используется для работы с данными Интернета вещей (IoT), например, для интеграции с устройствами для фитнеса и другими IoT-устройствами.
Таким образом, сравнение TimescaleDB и QuestDB зависит от конкретных потребностей проекта и его сферы применения. QuestDB может быть предпочтительным выбором в сфере финансовых технологий, где требуется высокая скорость обработки данных, в то время как TimescaleDB также предоставляет мощные инструменты для работы с данными временных рядов и может быть хорошим решением для других областей, таких как IoT и аналитика.
Актуальная версия
В этой обновленной версии поддерживается интеграция с СУБД PostgreSQL 12. При этом следует отметить, что поддержка версий PostgreSQL 9.6.x и 10.x больше не актуальна, и в будущей версии Timescale 2.0 будет поддерживаться только PostgreSQL 11 и выше.
Также важным изменением является обновление поведения запросов, использующих непрерывно выполняемые агрегатные функции. Теперь такие запросы объединяют материализованные представления с новыми данными, которые еще не были материализованы (ранее агрегация применялась только к уже существующим материализованным данным). Это новое поведение применяется к вновь созданным непрерывным агрегатам.
Кроме того, некоторые расширенные инструменты управления жизненным циклом данных были перемещены из коммерческой версии в версию сообщества. Эти инструменты включают в себя возможность перегруппировки данных и управление политиками удаления устаревших данных. Это позволяет эффективно управлять данными, хранить только актуальную информацию и автоматически удалять, архивировать или добавлять устаревшие записи в соответствии с заданными правилами.
Заключение
В заключение, TimescaleDB представляет собой мощное и гибкое решение для управления данными временных рядов в среде PostgreSQL. Его уникальная архитектура, включая гипертаблицы и чанки, позволяет эффективно обрабатывать большие объемы данных, что особенно важно в приложениях, где важна высокая производительность и скорость выполнения запросов. Благодаря богатому функционалу SQL и поддержке стандартных инструментов PostgreSQL, разработчики могут использовать TimescaleDB с минимальными усилиями и затратами на обучение.
Кроме того, TimescaleDB активно развивается и поддерживается сообществом, что обеспечивает его актуальность и надежность. Сравнительные тесты показывают, что в различных сценариях он может превосходить альтернативные решения, такие как ClickHouse и QuestDB. В целом, TimescaleDB отлично подходит для проектов, где требуется эффективное управление временными данными, будь то аналитика, IoT, финансовые приложения и многое другое.





