


Сервисы по распознаванию текста для бизнеса и интеграции с системами электронного документооборота (СЭД) играют важную роль в автоматизации и оптимизации рабочих процессов. Они позволяют преобразовывать отсканированные или фотографированные документы с текстом в машиночитаемый формат, что упрощает обработку и поиск информации.
Это, кстати, удивительно. Мы внедрили распознавание документов и интегрировали эту систему с СЭД. Теперь мы экономим около 10 FTE ежемесячно на рутинных работах по переписыванию документов в базу данных. Там, где раньше работало 11 человек, теперь работает 1, иногда 2. В основном, они следят за ошибками.
В целом, всё неплохо, но добавлю ложку дёгтя. Это интеграция. Чтобы она была максимально безболезненной API должен быть хорошо развит как на стороне OCR, так и на стороне СЭД. Такое бывает не всегда. Поэтому некоторые операции сперва у нас выполнялись вручную, потом стали использовать роботов RPA. Вот связка OCR+RPA+СЭД, пожалуй, действительно, творит чудеса.
Одной из основных функций таких сервисов является оптическое распознавание символов (OCR). При помощи сложных алгоритмов и технологий искусственного интеллекта они способны автоматически распознавать текст на изображении и преобразовывать его в электронный формат. Это значительно экономит время и снижает риски ошибок, связанных с ручным вводом информации.
Кроме того, сервисы по распознаванию текста для бизнеса могут интегрироваться с системами электронного документооборота (СЭД), такими как 1С:Документооборот, SharePoint и другими. Это позволяет автоматически передавать распознанный текст из документов в соответствующие системы, создавать электронные копии документов и облегчать их поиск и анализ.
Такие сервисы имеют широкий спектр применения в различных отраслях бизнеса. Например, они могут использоваться для автоматического распознавания и обработки счетов на оплату, товарных накладных, актов, контрактов и других бизнес-документов. В результате, компании могут улучшить эффективность работы, сократить затраты на обработку и хранение бумажных документов, а также повысить точность и доступность данных для принятия решений.
- Программы и сервисы, которые имеют собственный OCR-движок
- Content AI (преемник ABBYY в России)
- Smart Engines
- EasyDoc от компании ITFB
- Dbrain
- Beorg (БИОРГ)
- Soica
- Directum Ario One
- Tesseract OCR — open source решение, разработано HP, выкуплено Google
- Yandex Vision (пока только документы)
- Специализируются на распознавании, но работают на чужом OCR-движке
- Entera
- CORRECT от компании ТКсэт
- Fasta от компании EFSOL
- 1C: Распознавание первичных документов (от 1С и только для 1С)
- Что умеют распознавать эти сервисы и зачем это надо
- Документы, подтверждающие личность (паспорт, загранпаспорт, права и др.)
- Другие личные документы (СНИЛС, ИНН, ЕГРИП, выписки и др.)
- Бухгалтерские документы (счета, акты, счет-фактуры и др.)
- Транспортные документы (накладные, акты приемки-передачи и др.)
Программы и сервисы, которые имеют собственный OCR-движок
Ниже представлены сервисы для распознавания документов, которые включают собственный OCR-движок, специально разработанный для достижения высокой точности распознавания текста. Эти OCR-движки основаны на передовых алгоритмах машинного обучения и искусственного интеллекта, что позволяет им обрабатывать различные типы документов и разнообразные форматы файлов.
Собственный OCR-движок
Нет зависимости от внешних разработчиков OCR
Более сложная интеграция с СЭД
Может понадобиться внедрение RPA для осуществления интеграции
Быстрая скорость распознавания, высокая точность

Одно из преимуществ таких сервисов — их высокая скорость работы. Благодаря оптимизации алгоритмов и использованию мощных вычислительных ресурсов, они способны обрабатывать большие объемы документов за короткое время. Это особенно важно при работе с организациями, где требуется быстрый и эффективный обмен документами.
Однако, интеграция сервисов распознавания документов с системами электронного документооборота (СЭД) часто является сложной задачей. Это связано с необходимостью настройки соответствующих API-интерфейсов, обеспечения совместимости форматов данных, а также решения других вопросов, связанных с безопасностью и сохранностью информации. Каждая СЭД может иметь свои особенности и требования к интеграции, поэтому необходимо проводить тщательное исследование и взаимодействие с провайдерами обеих систем для успешного внедрения.
Content AI (преемник ABBYY в России)
Content AI — приемник решений мирового лидера в отрасли OCR, компании ABBYY, на территории России после ухода последней с российского рынка. Компания предлагает различные сервисы для бизнеса, разработчиков и персонального использования. Что касается OCR-решений, то они доступны для бизнеса в виде облачного и коробочного ПО, а также для разработчиков в формате SDK-библиотек.
В частности, ContentCapture — универсальная платформа для обработки информации из различных документов, включая рукописный текст, фотографии, электронные документы и письма. Она распознает, классифицирует и извлекает данные, ускоряя и упрощая процессы документооборота. Возможности включают распознавание рукописного текста, предобработку изображений, многоуровневую классификацию, защиту данных и обработку всех типов документов. ContentCapture также обладает гибкими возможностями интеграции с корпоративными информационными системами.
Другой сервис — ContentReader Server — корпоративное серверное решение для распознавания и преобразования файлов в PDF и другие редактируемые электронные форматы. Он оптимизирует документооборот, упрощает работу сотрудников и обеспечивает быстрый поиск документов. Решение позволяет хранить, передавать и обмениваться оцифрованными документами в едином формате. Его простота использования и интуитивный интерфейс не требуют специальной технической подготовки.
Сценарии использования включают создание электронных архивов для соблюдения стандартов, централизованный сервис конвертации документов для сотрудников, создание цифровых библиотек и сохранение культурного наследия, интеграцию с библиотеками на базе MS SharePoint и упрощение регистрации входящих документов в режиме «Канцелярия». ContentReader® Server обеспечивает быструю и точную обработку документов, уменьшая нагрузку на оборудование и обеспечивая удобный поиск по ключевым словам.
Smart Engines
Smart Engines — это компания, специализирующаяся на разработке программного обеспечения для распознавания документов с использованием передовых технологий искусственного интеллекта. Эти решения предназначены для автоматизации процесса извлечения информации из различных типов документов, таких как паспорта, водительские удостоверения, первичные бухгалтерские документы, банковские карточки, счета и другие.
В линейке представлено несколько продуктов:
- Smart Document Engine — то, что нас интересует больше всего в рамках этой статьи — классификация и распознавание множества различных документов, поддержка более 100 языков мира
- Smart ID Engine — тоже полезный инструмент в контексте статьи. Он обеспечивает распознавание и верификацию документов, удостоверяющих личность: паспорта РФ, а также паспортов, ID карт, водительских прав и других удостоверяющих документов РФ, ЕАЭС и всего мира.
- Smart Code Engine предназначен для сканирования банковских карт, MRZ (МЧЗ), QR-кодов, PDF417, AZTEC и других штрихкодов с индустриальным качеством
- Smart Tomo Engine для томографической реконструкции
Один из ключевых продуктов Smart Engines — это OCR-библиотеки (поставка в формате SDK), которые обеспечивают достаточно высокую точность и быстроту распознавания текста на изображениях документов и в видеопотоке.
Время распознавания данных разворота паспорта РФ на 1 кадре даже на мобильном телефоне составляет 0,15 секунды, а 1 страница УПД распознается прямо на смартфоне за 2-3 секунды. В серверных решениях без применения GPU можно на 32-ядерных процессорах добиться скорости распознавания 55 разворотов паспорта РФ в секунду, а на 64-ядерном HPC без применения GPU обеспечить полнотекстовое распознавание 15 страниц в секунду.
OCR-движок основан на передовых алгоритмах машинного обучения, которые позволяют точно распознавать разнообразные языки, шрифты и форматы документов. Решение также обладает способностью корректно извлекать структурированную информацию, такую как ФИО, даты, адреса и другие данные, что обеспечивает еще большую ценность при автоматизации бизнес-процессов.
Smart Engines предлагает гибкие интеграционные возможности. Решения могут быть интегрированы в различные системы, включая приложения для мобильных устройств, веб-сервисы и локальные серверы. Таким образом, они обеспечивают широкий спектр вариантов использования и адаптации к различным бизнес-потребностям.
EasyDoc от компании ITFB
EasyDoc — это российская система распознавания и извлечения данных из различных документов с помощью искусственного интеллекта. Она использует low-code/no-code разработку и микросервисную архитектуру. Система способна захватывать изображения из источников документов, проводить их предобработку, классифицировать документы, а затем извлекать и постобрабатывать атрибуты данных. Обладая высокой скоростью и точностью, она позволяет оптимизировать затраты и трудозатраты, а также обеспечивает безопасность и универсальность интеграции с другими системами.

Результаты работы системы включают быстрое извлечение данных из документов, сокращение обработки на 80%, высокую точность в распознавании данных, а также оптимизацию трудозатрат за счет задействования квалифицированных кадров на более интеллектуальных задачах. Система безопасна и устанавливается в контуре заказчика, обеспечивая возможность бесшовной интеграции с внешними системами посредством стандартизированного API.
Dbrain
Dbrain предлагает инновационные решения для распознавания документов, основанные на искусственном интеллекте. Их OCR-технологии позволяют извлекать данные из документов с высокой точностью всего за 3 секунды, значительно ускоряя процесс и сокращая затраты на обработку документов в пять раз. Сервис основан на передовых алгоритмах машинного обучения, которые обеспечивают высокую точность распознавания текста даже для различных типов документов и языков.
Базовая точность сервиса — 92%. Но она может быть повышена с помощью верификаторов. В этом случае достигается максимум — 99,5%.
Dbrain предлагает широкий спектр решений для различных бизнес-кейсов. Их OCR-технологии способны распознавать паспорта, водительские удостоверения, документы на автомобили, персональные документы и документы юридических лиц с высокой точностью до 99,5%. При необходимости точность распознавания может быть улучшена с помощью верификации данных специалистами.
Безопасность данных также является приоритетом для Dbrain. Все их продукты, включая OCR-решения, соответствуют требованиям законодательства о персональных данных, а данные клиентов обрабатываются в соответствии с законодательством. Система может работать как в облаке, так и в контуре клиента, обеспечивая дополнительные уровни безопасности.
Beorg (БИОРГ)
Компания предлагает несколько услуг по части распознавания документов: распознавание паспортов, оцифровка персональных документов, первичной бухгалтерской документации, работа с технической документацией, ОЦО, архивами и т.д. Является оператором персональных данных, а поэтому может обрабатывать документы на своих серверах (SaaS) с оплатой за фактически выполненный объем работ (pay-as-you-go).
Beorg Smart Vision — это платформа для сканирования и распознавания различных типов документов, включая бухгалтерские и кадровые. Она обеспечивает автоматическую обработку сложных и слабоструктурированных документов, включая рукописные, и безопасную передачу данных, повышая эффективность бизнес-процессов. С помощью искусственной нейронной сети документы анализируются и распознаются, а затем преобразуются в нужный формат для загрузки в информационные системы, такие как 1С или SAP.
Платформа также предлагает проверку комплектности документов, синхронизацию товарной номенклатуры и полную интеграцию с существующими системами без необходимости найма операторов 1С. Beorg Smart Vision работает как облачный сервис, обеспечивая защищенную обработку документов по защищенному каналу без необходимости приобретения специального программного обеспечения и оборудования.
Сервис гарантирует высокое качество и скорость обработки документов даже в периоды пиковых нагрузок благодаря технологии двойного ввода и деперсонализации данных. Beorg Smart Vision помогает сократить затраты и ускоряет переход на налоговый мониторинг, предоставляя надежное решение для обработки документов.
Soica
SOICA — это аббревиатура от Systems Of Intelligent Capture. Данное ПО обрабатывает различные типы документов, включая товарные накладные, счета-фактуры, акты, счета и паспорта. Он предоставляет удобный портал, на котором вы можете зарегистрироваться, скачать шлюз-программу для обработки документов в 1С и загрузить документы из сканера или проводника.

SOICA распознает и обрабатывает ваши документы, а затем 1С осуществляет массовое создание загруженных документов. Вы можете принять все загруженные документы одной кнопкой, а SOICA экспортирует их обратно в 1С.
Directum Ario One
Directum Ario One – система для интеллектуальной обработки документов и другой информации, разработанная российской ИТ-компанией Directum. Есть локальный и облачный варианты поставки. Локально система разворачивается на серверах заказчика, облачная версия размещается в ЦОД на территории Российской Федерации.
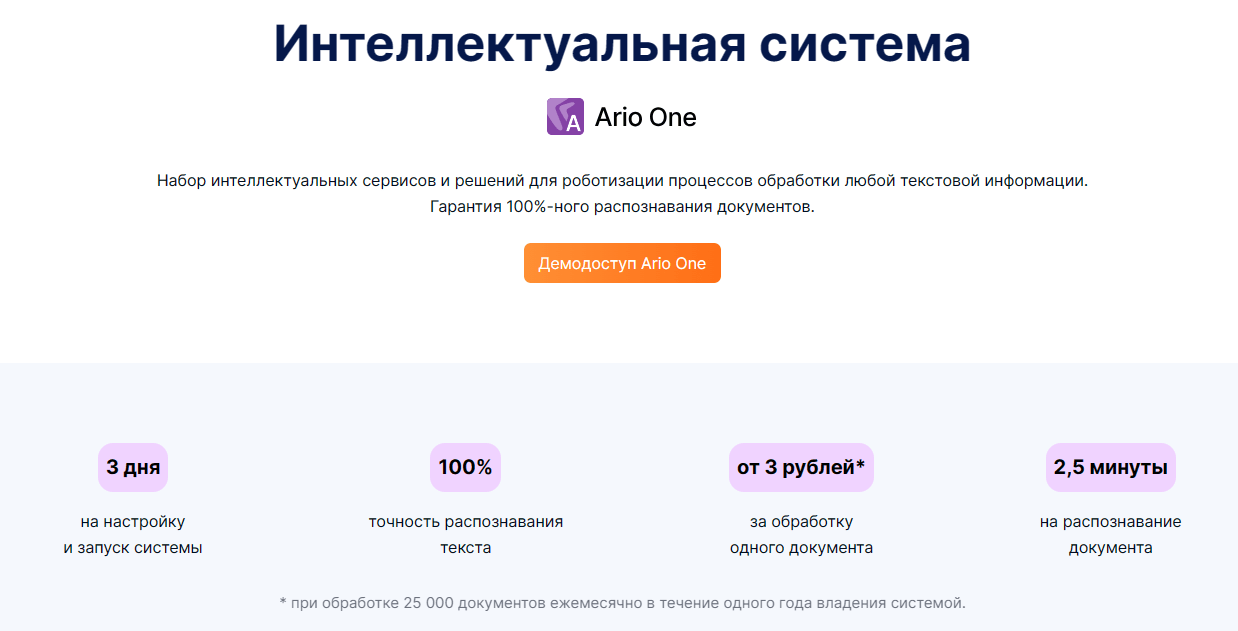
AI-продукт включает в себя набор интеллектуальных сервисов и решений для роботизации обработки любой текстовой информации. Берет на себя рутинные этапы работы, исключает человеческие ошибки, в разы ускоряет и удешевляет бизнес-процессы. На настройку и запуск системы требуется всего 3 дня. Скорость обработки документа – до 2,5 минут. Гарантируется 100%-ное распознавание документов.
Система решает такие рутинные задачи, как обработка входящей корреспонденции за секретаря, сверка номенклатур за бухгалтера, проверка текста договора на риски за юриста.
Интеллектуальная система Directum Ario One разработана в Российской Федерации, совместима с отечественным и свободно распространяемым ПО, соответствует критериям импортозамещения и рискоустойчивости к внешним санкциям. Способна заменить продукты зарубежных вендоров, например, Kofax Capture, Abbyy Flexicapture, EMC Captiva. Совместима с любой популярной ERP, CRM или HRM-системой.
Tesseract OCR — open source решение, разработано HP, выкуплено Google
Tesseract OCR (Optical Character Recognition) — это свободно распространяемый и открытый программный инструмент для распознавания текста на изображениях. Он разработан как часть проекта Tesseract, который начался в Hewlett-Packard Labs в конце 1980-х годов и позднее был продолжен и поддерживается Google.

Tesseract OCR способен обрабатывать различные типы изображений, включая сканированные документы, фотографии и снимки с камеры. Он обладает мощными алгоритмами и технологиями распознавания текста, позволяющими извлекать текстовую информацию из изображений и представлять ее в виде распознанных символов и слов.
Основные особенности Tesseract OCR включают поддержку нескольких языков, включая множество основных и редких языков, возможность обработки различных форматов изображений (включая TIFF, JPEG, PNG и другие), а также гибкие настройки и конфигурации для достижения наилучших результатов.
Tesseract OCR активно используется в различных сферах, включая автоматизацию бизнес-процессов, обработку документов, создание электронных архивов, распознавание номерных знаков, извлечение текста для машинного обучения и другие приложения, где требуется распознавание текста на изображениях.
Благодаря своей открытой природе и активному сообществу разработчиков, Tesseract OCR является популярным и широко используемым инструментом для распознавания текста, обеспечивая надежное и точное распознавание для различных задач и проектов.
Yandex Vision (пока только документы)
Это решение пока относится к числу начинающих и малофункциональных, но есть все шансы, что команда Яндекса расширит функционал и точность его работы. На данный момент его можно протестировать бесплатно.

Yandex Vision — это сервис, который предоставляет поддержку более 40 языков и работает с разными языковыми моделями. С его помощью можно легко интегрировать функциональность распознавания текста, классификации изображений, обнаружения лиц и распознавания автомобильных номеров в ваши приложения.
Сервис обладает высокой скоростью обработки, способен распознать текст на одной странице за несколько секунд и работает с несколькими изображениями на разных языках одновременно. Он предоставляет REST и gRPC API для интеграции с вашими приложениями, а также обеспечивает распознавание текста с указанием его расположения в виде блоков текста, строк и слов.
Технология классификации изображений позволяет анализировать и фильтровать контент, а функции обнаружения лиц и распознавания автомобильных номеров дополняют возможности сервиса, делая его универсальным инструментом для обработки различных типов данных и изображений.
Специализируются на распознавании, но работают на чужом OCR-движке
На рынке существует ряд сервисов, которые специализируются на распознавании текста и предлагают удобные решения для автоматизации этого процесса. Однако, важно отметить, что некоторые из этих сервисов оперируют с помощью сторонних OCR-движков.
Тут дело в том, что сервисы на чужом OCR лучше интегрируются в СЭД. Но скорость обработки страниц текста ниже — порой достигает 10-15 секунд.
Если нужно обработать большой объем страниц, придется покупать дорогой тариф и распараллеливать процессы распознавания. Кроме того, понадобятся мощные сервера, будь то собственные или облачные.
Использование сторонних OCR-движков имеет свои преимущества, такие как готовые и оптимизированные алгоритмы распознавания и широкая поддержка языков. Однако, это также означает, что сервисы, работающие на чужом OCR-движке, могут быть ограничены функциональностью и производительностью, предоставляемой самим движком. Кроме того, они могут не иметь полного контроля над обновлениями и улучшениями OCR-технологии.
Entera
С помощью Entera, пользователи могут избавиться от ручного внесения документов и использовать единый доступ к документам из различных систем электронного документооборота (ЭДО). Сервис также предлагает функции распознавания чеков, создания авансовых отчетов и отправки документов на распознавание с помощью электронной почты. Он оснащен потоковым распознаванием документов и электронным архивом для удобного хранения и доступа к документам.
Entera распознает данные из более чем 13 типов документов, включая УПД, счет-фактуры, товарные накладные, счета на оплату, акты, ТТН, кассовые чеки и другие. При создании документа в 1С, Entera автоматически прикрепляет PDF-файл скана, загруженного на распознавание. Вы также можете вручную прикреплять сканы только к необходимым документам для предоставления ссылки на распознанный документ в Entera, чтобы не перегружать базу 1С.
Entera позволяет загружать документы для распознавания в различных форматах, включая JPEG, PNG, TIFF, BMP, PDF, DOC, DOCX, XLS, XLSX, ODT, ODS, RTF.
Entera также автоматически распознает данные из отчета о реализации маркетплейса и создает отчет комиссионера в 1С. Основная идея сервиса заключается в упрощении и автоматизации процессов загрузки, распознавания и управления первичной документацией для повышения эффективности бухгалтерской работы.
Entera обеспечивает высокий уровень защиты данных и безопасности, сравнимый с онлайн-банками. Все данные шифруются с использованием проверенных протоколов и сертификатов, чтобы предотвратить утечку коммерческой информации. В договоре с Entera также присутствуют обязательные пункты о неразглашении информации. Получен сертификат соответствия ГОСТ Р ИСО/МЭК 27001-2005 (ISO/IEC 27001:2005) «Система менеджмента информационной безопасности при осуществлении деятельности по разработке программного обеспечения», что подтверждает высший уровень безопасности данных.
CORRECT от компании ТКсэт
CORRECT — это сервис распознавания документов, разработанный компанией ТКсэт. Сервис CORRECT использует технологии машинного обучения и искусственного интеллекта для автоматического распознавания и обработки различных типов документов.

С помощью CORRECT вы можете достичь точности распознавания до 100% и обработки до 3000 документов за 60 минут. Сервис обеспечивает быстрое подключение к системе 1С за 3 минуты и способен распознавать более 25 видов документов, включая счета, счета-фактуры, УПД, акты и другие. CORRECT также предлагает проверку корректности документов, сопоставление номенклатуры и формирование архива для удобного хранения документов. Сервис CORRECT имеет все необходимые лицензии и обеспечивает высокий уровень безопасности данных.
Сервис CORRECT позволяет сканировать и загружать документы в различных форматах, таких как изображения (JPEG, PNG) и PDF-файлы. С помощью сложных алгоритмов распознавания текста и оптического распознавания символов (OCR), CORRECT трансформирует изображения документов в электронный текст, который может быть дальше обработан и использован.
CORRECT обеспечивает высокую точность и эффективность в распознавании текста. Он автоматически распознает данные из различных типов документов, таких как счета, накладные, договоры и другие, и создает структурированные электронные версии этих документов.
Сервис CORRECT также предлагает функции проверки качества распознавания и возможность ручной корректировки результатов, чтобы обеспечить максимальную точность и соответствие оригинальным документам.
Fasta от компании EFSOL
Fasta — это программа, способствующая быстрому и точному вводу первичных документов в систему 1С. Она предоставляет возможность загружать документы для импорта прямо из партнерских источников, без необходимости сканирования. Путем добавления специальной обработки в 1С и предоставления вашего e-mail из сервиса Fasta партнерам, они могут отправлять вам документы непосредственно из 1С. Кроме того, Fasta также поддерживает загрузку сканов документов и фотографий.

Программа Fasta имеет сертификат «1С:Совместимо», что означает ее совместимость с системой программ «1С:Предприятие». Качество распознавания данных достигается за счет применения специализированных технологий ведущей компании ABBYY, которая специализируется в области распознавания текста и извлечения данных из различных документов. Программа использует современную платформу распознавания ABBYY FlexiCapture, которая является лидирующей технологией в области оптического распознавания текста.
Fasta является умным помощником, который помогает избежать ошибок, опечаток и неточностей, связанных с ручным вводом данных. Она позволяет загружать различные документы, такие как товарные накладные, счета-фактуры, универсальные передаточные документы (УПД), акты выполненных работ и счета на оплату. Сервис поддерживает распространенные форматы файлов, включая .XLS, .DOCX, .JPG и .PDF.
1C: Распознавание первичных документов (от 1С и только для 1С)
Сервис 1С:РПД предназначен для автоматического распознавания первичных документов, предназначенного для ускорения и упрощения ввода данных в базу 1С. Вот основные моменты, которые можно выделить:

- Сервис позволяет автоматически распознавать документы и избавляет от необходимости ручного ввода данных.
- Он обеспечивает потоковую загрузку и групповую обработку документов, что позволяет сэкономить время при большом объеме документов.
- Мобильное приложение 1С:Сканер документов позволяет передавать документы от удаленных сотрудников и может заменить стационарный сканер.
- Сервис автоматически прикрепляет сканы подписанных документов к ранее созданным документам в базе.
- Распознавание происходит внутри фирмы 1С и не передает документы третьим лицам, обеспечивая безопасность и защиту конфиденциальной информации и персональных данных.
- С помощью современных технологий искусственного интеллекта сервис корректно распознает бумажные документы и предлагает добавить недостающие данные на основе имеющейся базы объектов в 1С.
- Для использования сервиса требуется доступ в интернет, приложение 1С, поддерживающее сервис, и подписка на 1С:ИТС.
- Сервис доступен в различных приложениях 1С и имеет соответствующие тарифы, включая бесплатный тестовый пакет для пользователей ИТС.
- Инструкции по подключению и использованию сервиса можно получить у партнеров фирмы 1С.
Что умеют распознавать эти сервисы и зачем это надо
Из распознавания документов можно извлечь массу пользы. Здесь мы говорим об этом применительно к потребностям бизнеса и расширению возможностей СЭД.
Документы, подтверждающие личность (паспорт, загранпаспорт, права и др.)
Внедрение распознавания документов личности в систему электронного документооборота (СЭД) имеет несколько целей и преимуществ:
Мы потоком набираем менеджеров по продаже. Кто-то остается с нами надолго, кто-то быстро уходит. Но поток людей очень большой — десятки в день. Переписывать данные вручную трудоёмко. Распознавание упрощает процесс, в среднем, в 8 раз.
Стоит отметить, что современные формы документов удобны для распознавания. В старых паспортах часть данных, например, прописка, внесена вручную и плохо распознается. В новых документах таких проблем нет.
Да, мы тоже столкнулись с проблемой распознавания рукописных данных в старых паспортах. Даже если новые данные пропечатаны, то прописка и снятие с учета десятилетней давности заполнено от руки, и ни один OCR не распознает эти данные со 100% точностью.
- Идентификация личности: Распознавание документов личности, таких как паспорта или удостоверения личности, позволяет системе СЭД автоматически идентифицировать личность пользователей. Это обеспечивает безопасность и контроль доступа к документам и системе, предотвращает несанкционированный доступ и помогает предотвратить мошенничество.
- Автоматическое заполнение данных: Распознавание документов личности позволяет автоматически извлекать данные, содержащиеся в этих документах, и использовать их для заполнения соответствующих полей в СЭД. Это значительно ускоряет процесс ввода данных, снижает риск ошибок и улучшает точность информации.
- Упрощение процесса регистрации: При регистрации новых пользователей в системе СЭД распознавание документов личности позволяет автоматически считывать данные из предоставленных документов и использовать их для заполнения регистрационных форм. Это упрощает и ускоряет процесс регистрации новых пользователей, уменьшает необходимость вручную вводить данные и повышает точность информации.
- Улучшение документооборота: Распознавание документов личности в СЭД позволяет автоматически классифицировать и индексировать документы, основываясь на данных, извлеченных из этих документов. Это облегчает поиск, сортировку и организацию документов, делает процесс документооборота более эффективным и улучшает общую производительность и управляемость системы.
В целом, внедрение распознавания документов личности в СЭД способствует повышению безопасности, улучшению эффективности и точности обработки данных, а также упрощению процессов регистрации и документооборота.
Другие личные документы (СНИЛС, ИНН, ЕГРИП, выписки и др.)
Внедрение распознавания документов типа ИНН (Идентификационный номер налогоплательщика), ОГРНИП (Основной государственный регистрационный номер индивидуального предпринимателя), СНИЛС (Страховой номер индивидуального лицевого счета) и подобных в систему электронного документооборота (СЭД) предоставляет ряд преимуществ:
- Автоматическое заполнение данных: Распознавание документов типа ИНН, ОГРНИП, СНИЛС и других подобных позволяет автоматически извлекать соответствующие идентификационные данные из этих документов. Это упрощает и ускоряет процесс ввода данных, снижает риск ошибок и повышает точность информации.
- Идентификация и верификация данных: Распознавание документов типа ИНН, ОГРНИП, СНИЛС и подобных помогает системе СЭД автоматически проверять правильность введенных данных. Это позволяет установить соответствие между введенными и фактическими данными, предотвращая ошибки, некорректную идентификацию или использование недействительных данных.
- Быстрый доступ и поиск по данным: Распознавание документов типа ИНН, ОГРНИП, СНИЛС и других подобных позволяет системе СЭД эффективно классифицировать и индексировать документы на основе этих данных. Это облегчает поиск, сортировку и организацию документов, упрощая процесс их обработки и повышая общую производительность системы.
- Соблюдение правовых требований: В различных областях деятельности требуется соблюдение правовых требований и нормативов, связанных с обработкой и хранением данных типа ИНН, ОГРНИП, СНИЛС и подобных. Распознавание этих документов в СЭД позволяет обеспечить соответствие требованиям законодательства и обеспечить безопасность и конфиденциальность этих данных.
В целом, внедрение распознавания документов типа ИНН, ОГРНИП, СНИЛС и подобных в СЭД упрощает процессы ввода данных, повышает точность информации, обеспечивает соответствие правовым требованиям и повышает эффективность обработки и управления данными в системе.
Бухгалтерские документы (счета, акты, счет-фактуры и др.)
Распознавание бухгалтерских документов в СЭД имеет ключевое значение для повышения эффективности и точности бухгалтерского учета. Путем автоматического распознавания и извлечения данных из бухгалтерских документов, таких как счета, счета-фактуры, акты выполненных работ и другие, процесс обработки становится более быстрым, надежным и минимизируется риск ошибок, связанных с ручным вводом данных.
Распознавание бухгалтерских документов также позволяет упростить анализ и отчетность. Благодаря автоматической классификации и индексации документов, пользователи СЭД могут легко находить необходимую информацию для анализа финансового состояния, составления отчетов и принятия управленческих решений. Это сокращает время, затрачиваемое на поиск и обработку данных, и улучшает общую производительность бухгалтерского отдела. Распознавание бухгалтерских документов в СЭД является важным инструментом для оптимизации бухгалтерского учета, улучшения точности данных, снижения временных и финансовых затрат, а также обеспечения соответствия правовым требованиям.
Транспортные документы (накладные, акты приемки-передачи и др.)
Примерами транспортных документов, которые могут быть распознаны в СЭД, являются товарные накладные, включая ТОРГ-12 и накладные на доставку (ТТН), транспортные накладные, акты выполненных работ, счета и другие документы, связанные с логистикой и транспортировкой грузов.
Эти документы содержат информацию о грузе, отправителе, получателе, маршруте, услугах, стоимости и других существенных данных, которые могут быть распознаны и использованы для автоматической обработки и анализа в рамках СЭД.







