LLM (Large Language Model, большие языковые модели) открывают перед нами широкие горизонты возможностей в различных областях. От автоматизации рутинных задач до создания инновационных решений, LLM уже начинают трансформировать бизнес-процессы и повседневную жизнь. В их применении сочетаются мощные алгоритмы и обширные данные, что позволяет моделям быть не только эффективными, но и адаптивными к изменяющимся требованиям пользователей.

LLM становятся всё более совершенными и демонстрируют высокую степень понимания и способности к генерации текста. Благодаря использованию более сложных алгоритмов и больших объемов данных, эти модели способны создавать качественный контент, который раньше был возможен только с участием человека. Таким образом, ИИ-модели не только ускоряют выполнение задач, но и выводят их качество на другой уровень.
Введение
С развитием технологий, включая искусственный интеллект и обработку естественного языка, большие языковые модели приобретают все большую популярность. Эти системы способны генерировать текст, анализировать информацию и выполнять множество других задач, которые когда-то считались исключительно человеческими. В этом контексте становится очевидным, что LLM уже начинают влиять на множество аспектов нашей жизни, и их важность продолжает расти.
Давайте подробно рассмотрим, что такое ИИ-модели, как они работают и какие возможности открывают перед нами.
Что такое LLM и как это работает
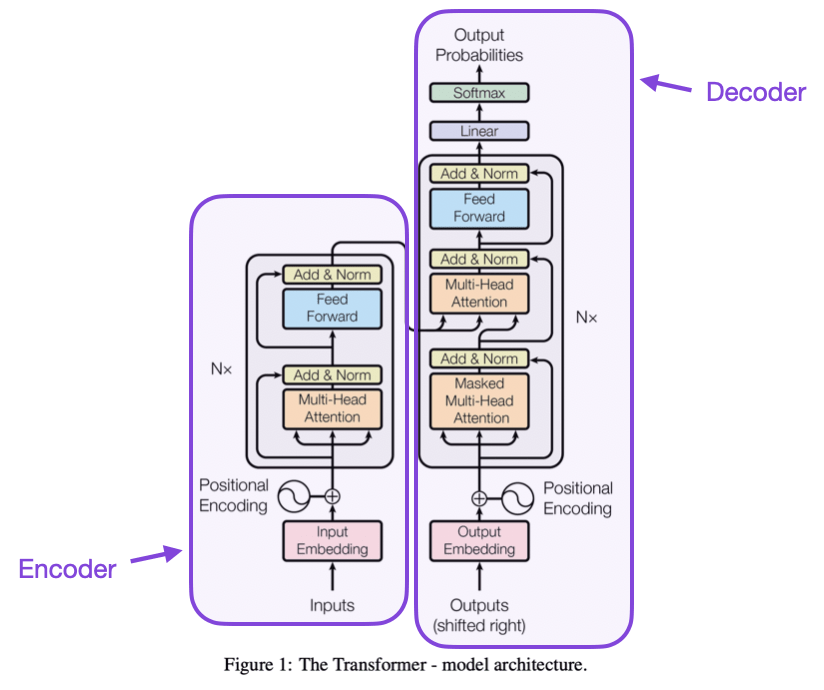
Большие языковые модели (Large Language Model, LLM) представляют собой массивные модели глубокого обучения, которые проходят предварительное обучение на гигантских объемах данных. В их основе лежит архитектура трансформера, которая включает набор нейронных сетей, состоящих из энкодера и декодера. Энкодер и декодер анализируют текстовые последовательности, определяя смысл и выявляя связи между словами и фразами.
Трансформер — это архитектура нейронной сети, которая революционизировала обработку естественного языка и многие другие задачи машинного обучения. Она была представлена исследователями Google Brain в статье «Attention is All You Need» в 2017 году и кардинально изменила подход к созданию моделей, используемых для понимания и генерации текстов.
Энкодер и декодер — это ключевые компоненты архитектуры трансформеров, используемые в больших языковых моделях (LLM).
- Энкодер принимает входной текст и преобразует его в числовые представления (векторные представления), сохраняя информацию о структуре и взаимосвязях слов. Основная задача энкодера — «закодировать» исходный текст таким образом, чтобы модель могла понять его смысл.
- Декодер использует закодированную информацию для генерации ответа или выполнения предсказаний. Он «раскодирует» полученные данные, создавая новые последовательности текста, учитывая предыдущие слова и контекст.
Эти компоненты работают совместно, позволяя модели анализировать текст и генерировать осмысленные ответы.
Как обучаются LLM
Обучение ИИ-моделей осуществляется на основе нейронных сетей, которые используют архитектуру трансформеров. Эти сети состоят из множества узлов, распределённых по уровням. Каждый узел на одном уровне связан с узлами на следующем, причём такие связи имеют свои веса и смещения, которые вместе с эмбеддингами образуют так называемые параметры модели. В больших трансформерных моделях количество этих параметров исчисляться миллиардами.
Размер модели напрямую зависит от числа параметров и объёма обучающих данных. Обучение происходит с использованием огромных массивов данных, которые проходят через сеть многократно. На каждом шаге модель корректирует свои параметры с целью повышения точности предсказания следующего токена на основе предыдущей последовательности токенов. Этот процесс основан на самообучении, при котором модель оптимизирует свои параметры, чтобы максимизировать вероятность правильного выбора следующих токенов.
После основного этапа обучения модель можно адаптировать для выполнения более конкретных задач. Это достигается с помощью так называемой точной настройки (fine-tuning), при которой используются небольшие наборы контролируемых данных для дообучения модели на решении конкретных задач. Этот процесс позволяет эффективно применять LLM в различных узкоспециализированных областях.
Почему LLM важны
Большие языковые модели обладают удивительной универсальностью. Одна и та же модель может решать разнообразные задачи, такие как ответы на вопросы, суммирование текстов, перевод на различные языки, генерация кода. LLM имеют потенциал значительно изменить процесс выполнения функций человека и, более того, уже частично его изменили.
Пусть LLM не идеальны, они демонстрируют способность делать точные прогнозы, даже если получают лишь минимальные входные данные. Их можно использовать в генеративных ИИ для создания контента на основе текстовых запросов, что значительно упрощает автоматизацию сложных процессов.
LLM огромны. Они способны обрабатывать сотни миллиардов параметров, что позволяет им успешно решать широкий спектр задач.
Возможности LLM
Возможности больших языковых моделей (LLM) действительно впечатляют, охватывая широкий спектр задач — от создания виртуальных помощников до генерации текста и кода. Рассмотрим несколько ключевых примеров использования LLM:
- ИИ-помощники. Развитие LLM привело к появлению мощных ИИ-помощников, способных решать разнообразные задачи: от помощи в программировании до организации задач и бронирования. Эти помощники, такие как Pi и ChatGPT, качественно превосходят традиционные голосовые ассистенты вроде Siri или Google Assistant. В отличие от ограниченных возможностей последних, LLM предлагают более гибкие и разнообразные решения, даже если запрос пользователя не до конца ясен.
- Чат-боты. ИИ-модели позволяют создавать чат-ботов, адаптированных к конкретным задачам. Такие боты могут отвечать на вопросы клиентов, основываясь на документации или данных пользователя. Особое значение здесь имеет технология Retrieval-Augmented Generation (RAG), которая усиливает возможности ботов. В то время как традиционные боты нуждались в сложных скриптах, современные модели способны вести гибкий и разнообразный диалог, будь то заказ пиццы или обсуждение повседневных тем.
- Генерация контента. LLM способны генерировать текстовые фрагменты на основе вводных данных. Они могут использоваться для написания статей, маркетингового контента, кодирования и других текстовых задач. Это кардинально меняет подход к творческим профессиям: многие начинают использовать ИИ-модели для ускорения работы, например, для создания блогов, маркетинговых стратегий или даже сценариев для интервью. Таким образом, LLM стали инструментом, который позволяет генерировать качественный контент в кратчайшие сроки.
- Перевод. LLM отлично справляются с задачами перевода текстов, а также способны выполнять более сложные задачи, такие как перевод на языки программирования. Примером здесь является модель Code Llama, которая может генерировать код на основе текстовых запросов. Недавние исследования показывают, что многие последние модели уже способны превосходить специализированные API, такие как Google Translate или DeepL, особенно на творческих текстах и редких языках. Это ускоряет процесс общения между людьми из разных стран и упрощает взаимопонимание.
- Резюмирование. Эффективное сокращение длинных документов, делая информацию доступнее и понятнее. Например, можно обобщить отчёт на 100 страниц в краткое изложение или выделить ключевые моменты из часовой видеозаписи. С использованием моделей вроде GPT-4о эта задача становится максимально простой: достаточно загрузить документ, и в ответ вы получите краткое резюме с основной информацией.
- Поиск. Поисковые системы на основе LLM значительно превосходят традиционные поисковые механизмы, основанные на ключевых словах. Такие системы, как Google с генеративным поиском и Perplexity AI, предлагают более точные и релевантные результаты, анализируя контекст запроса пользователя. Модели упрощают настройку фильтров и определение того, что именно хочет пользователь, избавляя от необходимости строить сложные системы на основе машинного обучения.
Эти примеры — лишь часть того, на что способны большие языковые модели.
Галлюцинации LLM и как их минимизировать
Галлюцинации у LLM возникают, когда модель теряет точное понимание вопроса или сталкивается с неполными или ошибочными данными, на которых она обучалась. В такой ситуации модель пытается угадать ответ, опираясь на имеющиеся шаблоны, что может привести к неверной информации.
Галлюцинация LLM — это феномен, когда большая языковая модель, такая как GPT или другой ИИ, генерирует фактически неверные или вымышленные данные, которые не основаны на реальной информации.

Что интересно, такие забавные галлюцинации могу не уходит и спустя годы обучения.
На тот же самый вопрос одна из флагманских моделей на момент 2024 года, GPT-4o mini, ответила похожим образом:

Модель не способна знать больше того, чему была обучена, и, сталкиваясь с пробелами в данных, может начать галлюцинировать, то есть генерировать неточные или вымышленные ответы.
Это может проявляться в виде неправильных фактов, несоответствующих выводов, или даже полностью выдуманных понятий, не существующих в реальности. Проблема заключается в том, что модели могут создавать очень уверенные ответы, которые выглядят правдоподобными, даже если они ошибочны.
Хотя в некоторых случаях неожиданные ответы могут быть полезны, особенно в творческих задачах, в других ситуациях важно минимизировать ошибки. Для этого можно применить следующие подходы:
- Правильные промты. Промт — это специально сформулированный запрос для нейросети. Профессия промт-инженера стала популярной, потому что не все умеют находить общий язык с большими языковыми моделями. Нейросетям особенно интересны конкретные задачи. Также ИИ охотно реагирует на примеры.
- Обучение с контекстом. Когда модель обучена с учётом контекста или определённой темы разговора, она становится способна более точно отвечать на вопросы. Без этого контекста модель может запутаться и выдавать нерелевантные ответы. При подаче запроса стоит включать как можно больше информации, которая может быть полезна для задачи.
- Ограничение вариантов ответа. Чтобы минимизировать вероятность неправильных ответов, можно сформулировать вопрос так, чтобы модель не могла отвечать слишком свободно. Например, дать ей варианты ответов, если это возможно. Это ограничит её возможность создавать вымышленные данные.
- Специальные модели для точных ответов. Существуют модели, которые разработаны специально для точного извлечения данных с минимальными галлюцинациями. Например, WizardLM — это небольшие модели, которые можно запустить даже на обычных видеокартах. Такие модели особенно подходят для корпоративных данных, где важна высокая точность ответов.
Если соблюдать основные особенности и правила создания запроса, шансы на галлюцинации уменьшаются:
Однако важно помнить, что полностью исключить ошибки у модели невозможно. Даже при всех вышеуказанных мерах LLM всё равно иногда будут выдавать неверные ответы, и их может быть сложно сразу заметить.
Заключение
Большие языковые модели открывают новые горизонты в области обработки естественного языка и искусственного интеллекта, предоставляя мощные инструменты для генерации текста, анализа данных и автоматизации множества процессов. Их способность адаптироваться к различным задачам и эффективно взаимодействовать с пользователями свидетельствует о значительном прогрессе в этой области. Несмотря на существующие ограничения и возможность возникновения галлюцинаций, LLM продолжают развиваться, улучшая точность и надежность своих ответов.
В будущем можно ожидать, что LLM станут еще более интегрированными в нашу повседневную жизнь, применяясь в бизнесе, образовании и других сферах. Их влияние будет только расти, и с каждым новым достижением мы будем всё ближе к созданию систем, способных на что-то большее. Развитие LLM открывает возможности для более эффективного взаимодействия между человеком и машиной, что, безусловно, изменит наш подход к многим аспектам жизни.