




Искусственный интеллект продолжает активно развиваться, и 2024 год стал свидетелем значительных достижений в области языковых моделей. Сейчас искусственный интеллект и языковые модели на его основе играют большую роль в автоматизации процессов, улучшении пользовательского взаимодействия и создании интеллектуальных решений для бизнеса и различных сфер жизни.

Сегодня на рынке представлено множество конкретных больших языковых моделей (LLM), каждая из которых имеет свои уникальные характеристики и особенности. Узнаем подробнее о лучших ИИ-моделях 2024 года, сравним их по основным характеристикам и сделаем выводы.
- Введение
- Как выбрать ИИ-модель?
- Сравнение ИИ-моделей
- Индекс качества (Artificial Analysis Quality Index)
- Понимание языка и рассуждения (Reasoning & Knowledge, MMLU)
- Научное рассуждение и знание (Scientific Reasoning & Knowledge, GPQA)
- Решение математических задач и математическая логика (Quantitative Reasoning, MATH)
- Генерация кода на основе текста (Coding, HumanEval)
- Стоимость
- Задержка
- Контекстное окно
- Рейтинг ИИ-моделей 2024
- Место №1. OpenAI
- Последние версии
- Сравнение версий
- Место №2. Meta AI*
- Последние версии
- Сравнение версий
- Место №3. Google DeepMind
- Последние версии
- Сравнение версий
- Место №4. Anthropic
- Последние версии
- Сравнение версий
- Место №5. Mistral AI
- Последние версии
- Сравнение версий
- Место №6. Deepseek
- Последние версии
- Сравнение версий
- Место №7. AI21 labs
- Последние версии
- Сравнение версий
- Место №8. Perplexity
- Последние версии
- Сравнение версий
- Место №9. Reka
- Последние версии
- Сравнение версий
- Место №10. Cohere
- Последние версии
- Сравнение версий
- Критерии сравнения
- Заключение
Введение
Большие языковые модели (Large Language Model, LLM) представляют собой массивные модели глубокого обучения, которые проходят предварительное обучение на гигантских объемах данных.
2024 год стал очень конкурентным для разработчиков ИИ, которые предлагают решения с похожими, но все же отличными характеристиками и особенностями. Некоторые из моделей отличаются своей универсальностью, другие специализируются на выполнении узкоспециализированных задач.
Важно учитывать, что выбор конкретной ИИ модели всегда зависит от специфики бизнес-задачи и требуемого результата. Для обработки естественного языка одна модель может быть оптимальной, в то время как для анализа больших объемов данных предпочтение стоит отдать другой архитектуре. Компании должны четко определять свои цели, будь то улучшение клиентского обслуживания, автоматизация процессов или прогнозирование. Выбор модели, соответствующей этим потребностям, позволяет повысить эффективность и снизить затраты на внедрение и эксплуатацию ИИ решений.
Рассмотрим 10 наиболее популярных видов языковых моделей 2024 года, сравним их по ключевым параметрам и обсудим их преимущества и недостатки. Уделим внимание таким важным аспектам, как лицензирование, что оказывает влияние на коммерческое использование и распространение этих технологий.
Как выбрать ИИ-модель?
Выбор идеальной языковой модели — это не просто вопрос цифр и рейтингов. Прежде всего, важно задать себе несколько ключевых вопросов. Какую задачу вы хотите решить? Какие данные у вас есть? Какая скорость отклика вам нужна? Сколько вы готовы потратить на реализацию ваших запросов? Ответы на эти вопросы помогут определить, какая модель станет наилучшим выбором.
Если идет речь о бизнесе, стоит рассмотреть не только технические характеристики, но и возможности интеграции выбранной модели с существующими системами. Подумайте о будущем: будет ли ваша задача изменяться? Возможно, вам нужна модель, способная адаптироваться к новым требованиям и задачам.
Таким образом, подходя к выбору осознанно, вы сможете не только оптимизировать свой бизнес и избежать нежелательных расходов, но и упростить массу задач в повседневной жизни. Каждый шаг, начиная от определения задачи и заканчивая выбором модели, имеет значение.
Сравнение ИИ-моделей
Общее сравнение позволит определить сильные и слабые стороны каждой из представленных ИИ на основе их одной лучшей модели. Опираться будем на ключевые показатели: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка и Контекстное окно.
Сравнивая модели по указанным критериям, мы сможем не только оценить их производительность, но и понять, какая из них более экономична и эффективна в контексте практического применения. Учитывая специфику каждой модели, результаты анализа позволят сделать обоснованные выводы о выборе оптимального решения для различных задач в области обработки естественного языка.
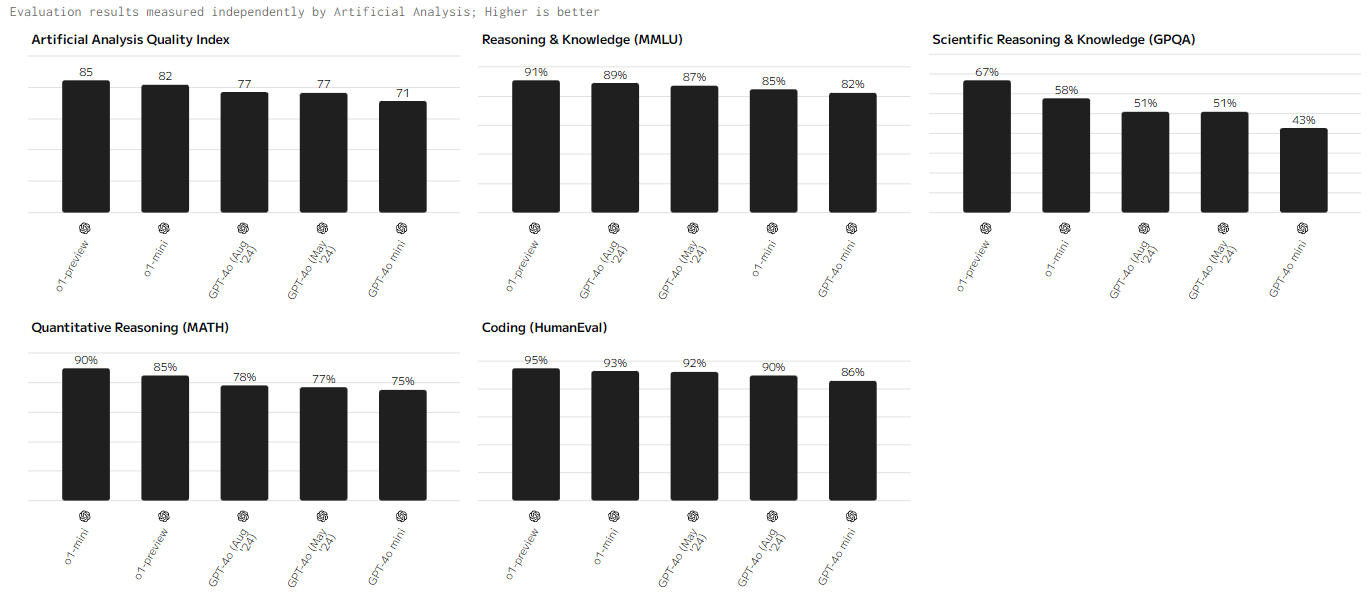
Индекс качества (Artificial Analysis Quality Index)
Лидером по Artificial Analysis Quality Index является модель o1-preview, набравшая 85 баллов. Она значительно опережает другие модели, такие как Claude 3.5 Sonnet и Mistral Large, которые набрали 77 и 73 балла соответственно. Llama 3.1 40B и Gemini 1.5 Pro также показали достойные результаты, с оценками 72 балла. В то же время модели, такие как Reka Core и Command-R+, находятся внизу рейтинга с оценками ниже 60 баллов, что говорит о их более ограниченных возможностях.
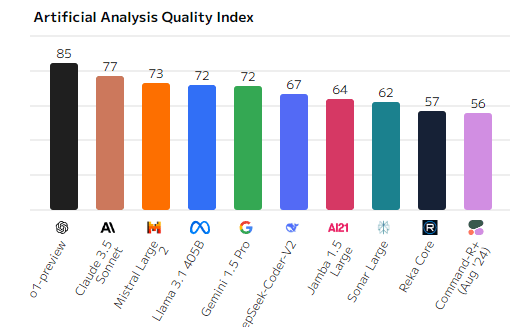
Понимание языка и рассуждения (Reasoning & Knowledge, MMLU)
Раздел логики и знаний показал, что o1-preview снова лидирует, достигнув 91%, что указывает на её высокий уровень анализа и знаний. Claude 3.5 Sonnet и Llama 3.1 40B также демонстрируют сильные результаты, с 88% и 87% соответственно. Mistral Large и Gemini 1.5 Pro продолжают находиться в верхней части рейтинга, показывая отличные результаты по задачам логического анализа. Однако Reka Core и Command-R+ снова остаются в нижних позициях с результатами ниже 50%.
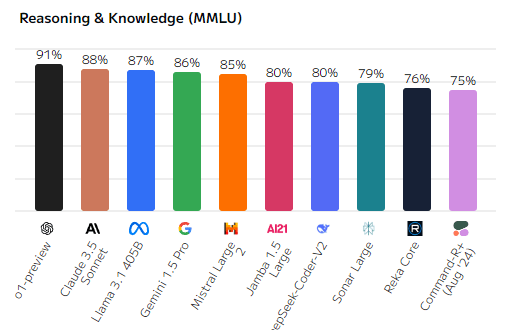
Научное рассуждение и знание (Scientific Reasoning & Knowledge, GPQA)
Для научных знаний и логики лидером опять становится o1-preview, набирая 67%. Claude 3.5 Sonnet заняла второе место с 56%, а Llama 3.1 40B показала 50%. Этот показатель особенно важен для задач, связанных с научными и техническими данными. Mistral Large и Gemini 1.5 Pro также показали удовлетворительные результаты, но модели с более низкими баллами, такие как Jamba 1.5 Large и Reka Core, показали более ограниченные возможности в этой области.
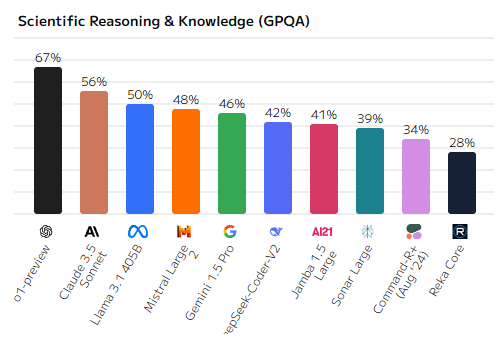
Решение математических задач и математическая логика (Quantitative Reasoning, MATH)
Математические способности ИИ-моделей также имеют ключевое значение, и здесь вновь o1-preview занимает первое место с 85%. Claude 3.5 Sonnet и Mistral Large идут следом с результатами 74% и 72% соответственно. Это подчеркивает их способность эффективно решать задачи, требующие математической логики и расчётов. Jamba 1.5 Large и Reka Core продемонстрировали результаты ниже 60%, что указывает на их более слабую производительность в математике.
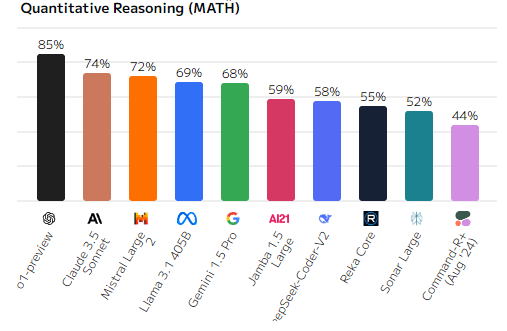
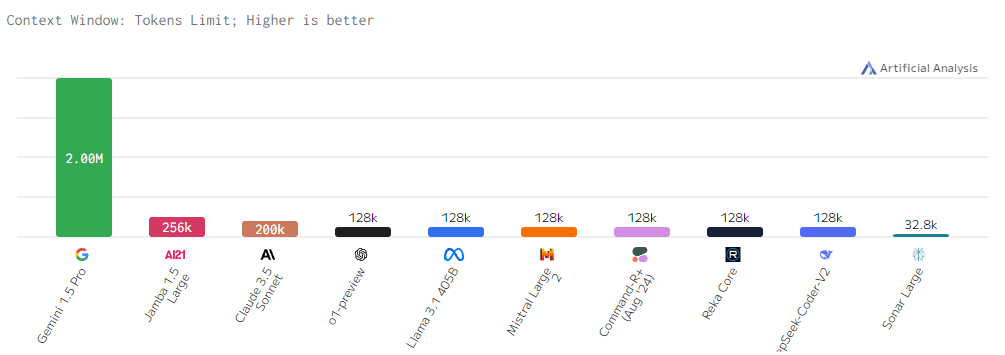
Генерация кода на основе текста (Coding, HumanEval)
Задачи программирования требуют высокого уровня понимания кода и алгоритмов. o1-preview снова занимает лидирующую позицию, демонстрируя 95% успеха в кодировании. Claude 3.5 Sonnet и Mistral Large следуют за ней с 90% и 87%, что говорит о их высоких возможностях в программировании. Однако модели, такие как Command-R+ и Reka Core, снова оказались на нижних местах с результатами ниже 70%.
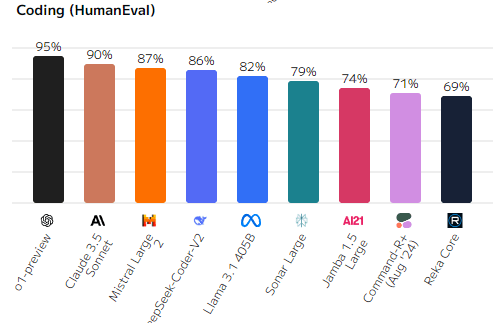
Стоимость
Диаграмма наглядно демонстрирует значительные различия в стоимости использования различных языковых моделей ИИ. Стоимость, как показано, зависит от множества факторов, включая сложность модели, объем обрабатываемых данных и набор доступных функций.
Наиболее заметным является широкий диапазон цен на рынке. Это говорит о том, что существует модель для каждого кошелька и потребности. Однако, следует помнить, что более высокая стоимость часто коррелирует с более высокими показателями качества, такими как точность, скорость обработки и разнообразие функций. В то же время, для многих задач вполне достаточно более бюджетных решений. При выборе модели необходимо тщательно взвешивать соотношение цены и качества, а также учитывать специфику решаемой задачи.
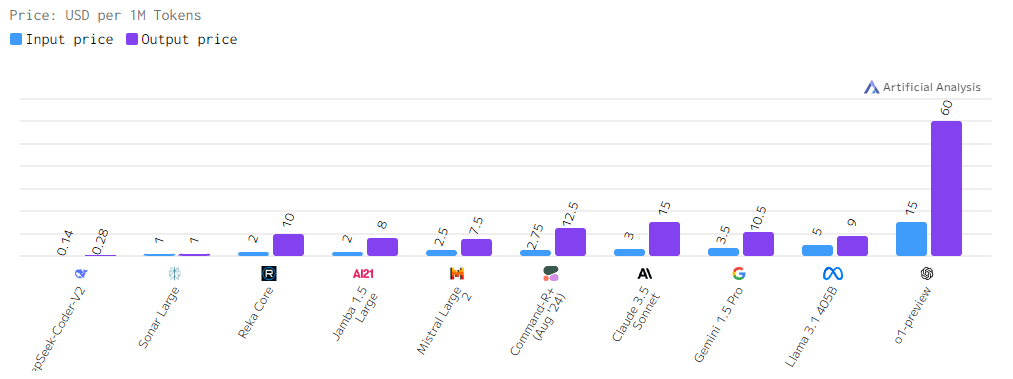
Задержка
На диаграмме прослеживается значительный разброс в скорости работы разных моделей. Некоторые модели, такие как Sonar Large и Mistral Large, демонстрируют очень высокую скорость обработки, предоставляя ответ практически мгновенно. В то же время, модель o1-preview значительно отстает от остальных, требуя как минимум в 30 раз больше времени для обработки запроса.
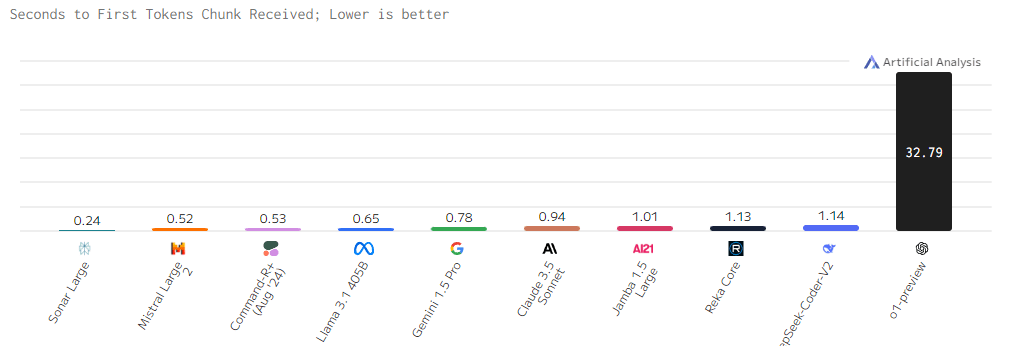
Контекстное окно
Представленная диаграмма демонстрирует существенные различия в способности языковых моделей обрабатывать длинные тексты. Этот параметр, называемый контекстным окном, определяет максимальное количество слов или частей слов, которые модель может «помнить» при выполнении задачи.
Чаще всего встречается прослеживается контекст размером в 128k. o1-preview, занявший лидирующее место в рейтинге, как раз и обладает этим самым усредненным значением в 128k, однако это не мешает модели показывать самые высокие результаты по индексу качества в 2024.
А вот Gemini 1.5 Pro опережает каждого, имея самое большое контекстное окно в 2M. Это означает, что она может работать с более длинными и сложными текстами, например, суммировать обширные документы, генерировать длинные коды или поддерживать продолжительные диалоги. Другие модели, хотя и демонстрируют хорошие результаты, без шансов уступают Gemini 1.5 Pro в этом аспекте.
Рейтинг ИИ-моделей 2024
Каждая из 10 видов языковых моделей в рейтинге включает в себя некоторое количество версий, которые, в свою очередь, справляются с различными задачами в каждой области по-разному. Сравним и выясним, каким ИИ-моделям стоит отдать предпочтение в тех или иных областях и сравнительных характеристиках.
Список рассматриваемых моделей (самые последние версии):
- OpenAI: o1-preview, o1-mini, GPT-4o, GPT-4o mini.
- Meta AI*: Llama 3.1 405B, Llama 3.1 70B, Llama 3.1 8B.
- Google DeepMind: Gemini 1.5 Pro, Gemini 1.5 Flash.
- Anthropic: Claude 3.5 Sonnet, Claude 3 Opus, Claude 3 Haiku.
- Mistral AI: Mistral Large 2, Mixtral 8x22B, Mistral Small.
- Reka: Reka Core, Reka Flash, Reka Edge.
- Cohere: Command-R+, Command-R.
- Perplexity: Sonar Large, Sonar Small.
- AI21 labs: Jamba 1.5 Large, Jamba 1.5 Mini.
- Deepseek: DeepSeek-Coder-V2, DeepSeek-V2, DeepSeek-V2.5.
*Деятельность Meta Platforms Inc. и принадлежащих ей социальных сетей Facebook и Instagram запрещена на территории РФ.
Место №1. OpenAI
OpenAI — лидер на рынке ИИ. Компания известна своими инновациями в области LLM и активно работает над созданием технологий, которые могут помочь решать глобальные проблемы, улучшать бизнес-процессы и развивать пользовательский опыт. ChatGPT — самый популярный ИИ-продукт не только в рамках компании, но и в всем мире, который где только не используют — от чат-ботов до инструментов для программирования и анализа данных.

Последние версии
o1-preview — самая мощная языковая модель на рынке, последняя разработка OpenAI. ИИ-модель создана специально для решения сложных задач в различных областях. Она обучена с использованием методов обучения с подкреплением, что позволяет ей производить более глубокие и обоснованные ответы.
«o» в названиях моделей означает «omni» — универсальность и способность обрабатывать различные виды данных и задач
o1-mini — это облегченная версия o1-preview, предлагающая более быструю и экономичную обработку. Эта модель особенно эффективна для задач, связанных с программированием, математикой и естественными науками. Основные характеристики o1-mini:
GPT-4o — это продвинутая и самая первая multimodal модель от OpenAI. GPT-4o позволяет принимать как текстовые, так и графические входные данные, а затем генерировать ответы.
GPT-4o mini — это мини-версия GPT-4o для более легких задач, которая сохраняет высокую степень интеллекта, и при этом является доступной и быстрой. Эта модель подходит для выполнения задач, требующих меньших ресурсов.
Сравнение версий
Сравним все четыре версии по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
Индекс качества (Artificial Analysis Quality Index)
Модель o1-preview лидирует по большинству ключевых показателей, демонстрируя высокую производительность. Мини-версия показывает схожие результаты, немного уступая старшей версии. В то же время модели GPT-4o отстают, что подчеркивает их более узкую специализацию и применение в задачах с меньшими требованиями к вычислительной мощности.
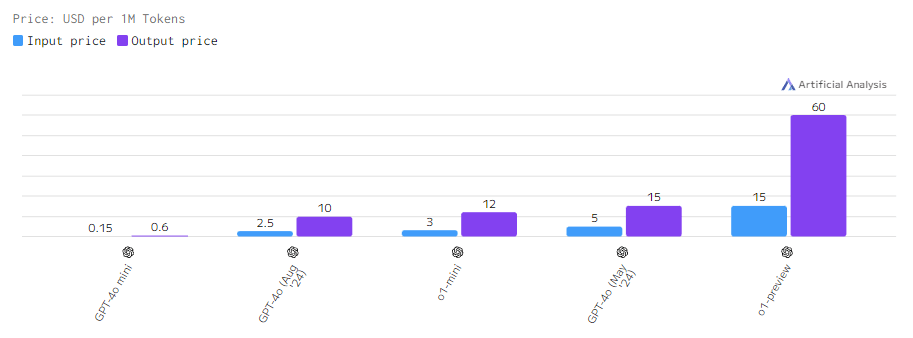
Стоимость
Стоимость пропорциональна качеству. o1-preview — самая мощная и дорогая ИИ-модель на рынке. Предыдущие версии куда дешевле, но все же менее производительны.
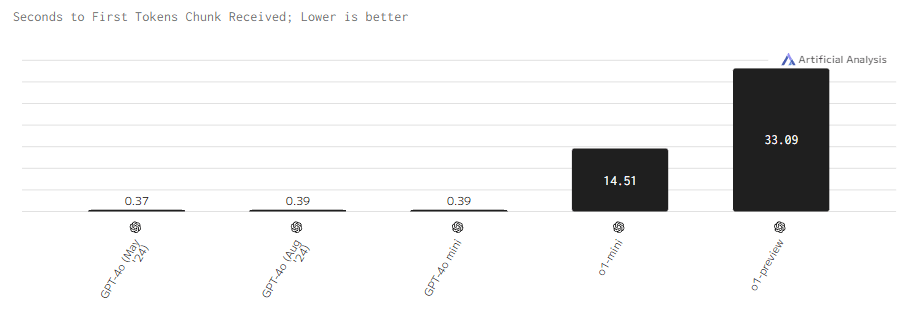
Задержка
С задержкой похожая ситуация. Последним моделям нужно куда больше мощностей на обработку запросов, что требует больше времени.
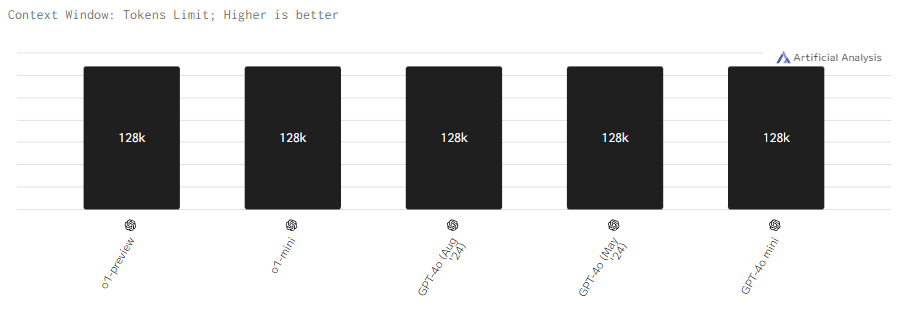
Контекстное окно
С длинной контекста всё еще проще: он у всех моделей одинаковый — 128k.
Место №2. Meta AI*
Meta AI* активно конкурирует на рынке ИИ с серией языковых моделей Llama 3.1, предлагая решения с различными параметрами для удовлетворения разнообразных задач. Эти модели отличаются высокой производительностью и эффективностью в обработке данных. Компания активно исследует, как ИИ может улучшить взаимодействие пользователей и расширить возможности социальных сетей. Их технологии применяются в различных сферах, включая автоматизацию контента, создание чат-ботов и инструменты для анализа пользовательских данных.

Последние версии
Llama 3.1 405B — это самая мощная версия в серии Llama, обладающая 405 миллиардами параметров. Она предназначена для решения сложных задач, требующих высокой вычислительной мощности. Модель демонстрирует отличные результаты в генерации текстов и анализе данных, а также подходит для мультимодальных приложений.
Llama 3.1 70B представляет собой компромисс между производительностью и ресурсами. С 70 миллиардами параметров эта модель обеспечивает быстрое выполнение задач и идеально подходит для разработки чат-ботов и аналитических инструментов, где важна высокая скорость обработки, но не критична максимальная мощность.
Llama 3.1 8B — самая легкая модель из рассматриваемых, предлагающая экономичное решение для задач, не требующих высокой вычислительной мощности. С 8 миллиардами параметров она подходит для простых приложений и задач, связанных с текстовой обработкой, обеспечивая хорошую производительность при ограниченных ресурсах.
Сравнение версий
Сравним все четыре версии по следующим показателям:Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
Индекс качества (Artificial Analysis Quality Index)
Llama 3.1 405B лидирует по всем параметрам, обеспечивая наилучшие результаты среди всех моделей. Llama 3.1 70B также демонстрирует достойные показатели, однако уступает своей старшей версии. А вот Llama 3.1 8B показывает уже скромные результаты на фоне своих старших моделей, что обусловлено её меньшими возможностями.

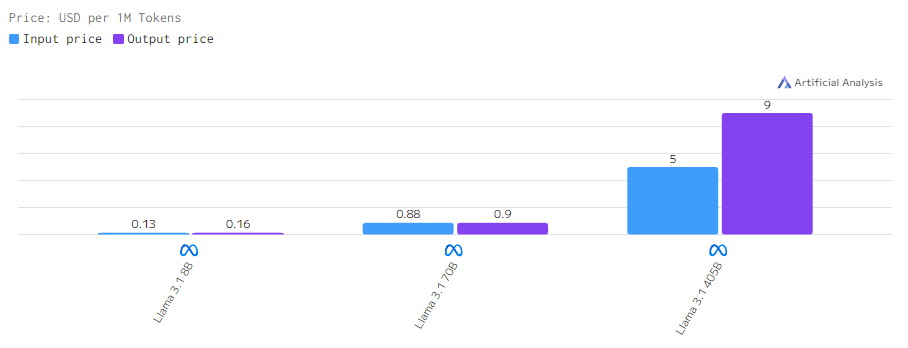
Стоимость
Новые модели дороже, старые дешевле. Обусловлено мощностью. Чем ее больше нужно, тем дороже это обойдется компании и, само собой, пользователям.
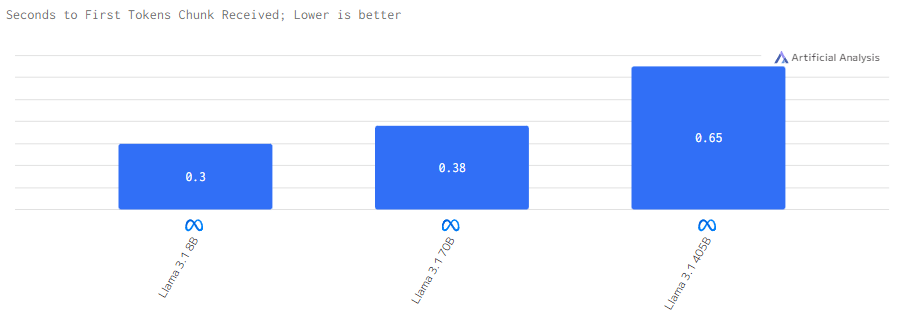
Задержка
LIama 3.1 405B требует больше мощностей на обработку запросов, что занимает больше времени. Менее энергозатратные модели требуют в разы меньше времени на реализацию токенов.
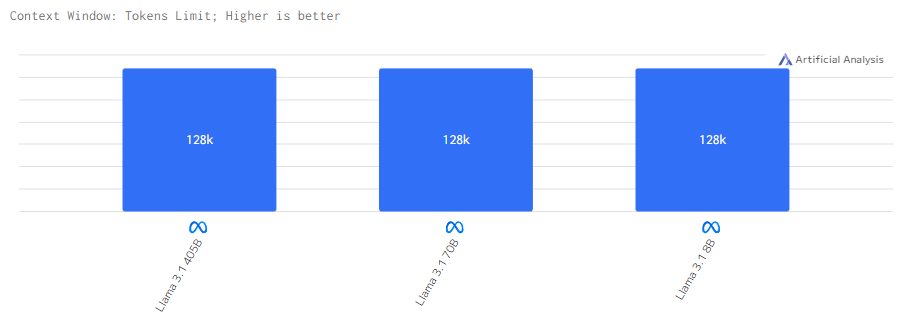
Контекстное окно
Длина контекста всё та же для всех — 128k.
Место №3. Google DeepMind
Google DeepMind продолжает оставаться в числе лидеров в области искусственного интеллекта благодаря своим передовым разработкам в сфере языковых моделей. Их новейшие версии, Gemini 1.5 Pro и Gemini 1.5 Flash, демонстрируют высочайшие результаты в различных тестах, что делает их подходящими для решения сложных задач, включая обработку больших объемов данных, генерацию текста и автоматизацию процессов. Google активно интегрирует свои модели в сервисы и приложения, что повышает их универсальность и применимость в широком спектре отраслей.

Последние версии
Gemini 1.5 Pro является самой продвинутой моделью от Google DeepMind, обладая значительным количеством параметров и высокой вычислительной мощностью. Она оптимизирована для сложных задач, включая генерацию текста, анализ данных и решение задач с мультимодальными входами. Эта модель может быть применена в различных областях, включая разработку ПО, автоматизацию бизнес-процессов и создание интеллектуальных систем поддержки принятия решений.
Gemini 1.5 Flash — это облегченная версия Pro, которая предназначена для тех случаев, когда важна скорость обработки данных и экономичность использования вычислительных ресурсов. Модель сохраняет значительную часть функциональности старшей версии, но лучше подходит для задач с меньшими требованиями к вычислительным мощностям, таких как чат-боты, генерация простых текстов и анализ базовых данных.
Сравнение версий
Сравним все четыре версии по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
Индекс качества (Artificial Analysis Quality Index)
Gemini 1.5 Pro показывает выдающиеся результаты, особенно в задачах, требующих обработки больших объёмов данных и высокой точности. Модель отличается мощной поддержкой мультимодальных приложений и может работать с большими наборами данных. Gemini 1.5 Flash демонстрирует немного меньшую производительность, уступая Pro по точности и глубине обработки, но остаётся эффективной для менее требовательных задач.

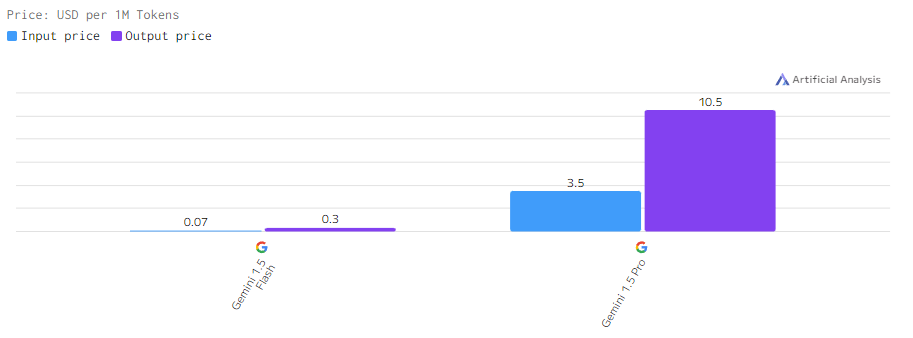
Стоимость
Стоимость использования моделей Google DeepMind коррелирует с их мощностью. Gemini 1.5 Pro стоит дороже за обработку миллиона токенов по сравнению с Gemini 1.5 Flash, что связано с более высокими вычислительными требованиями старшей модели. Flash представляет собой более бюджетный вариант, сохраняя при этом достойные показатели производительности.
Задержка
Задержка у Gemini 1.5 Pro выше из-за большего объема вычислений, необходимых для обработки сложных задач. Flash, напротив, демонстрирует меньшую задержку, что делает её оптимальной для приложений, где важна высокая скорость ответа, например, в интерактивных чат-ботах.
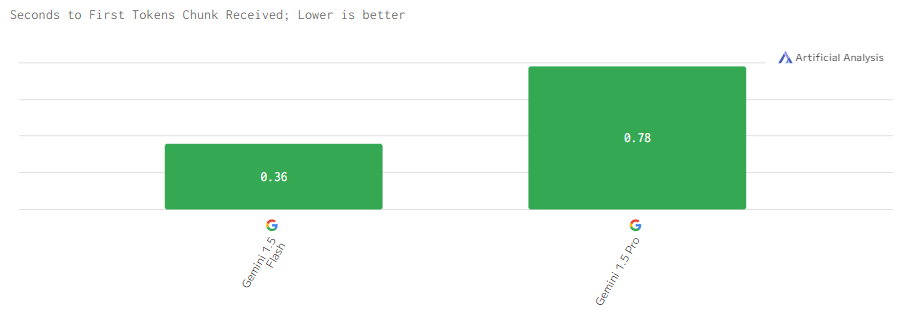
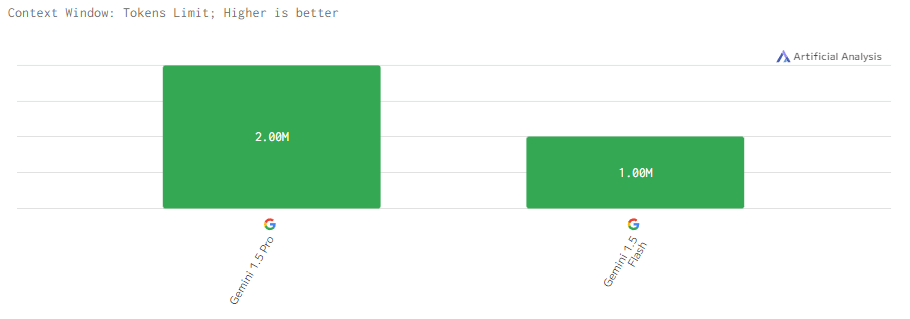
Контекстное окно
А вот тут становится интересно. Среди всех ИИ-моделей на рынке Gemini 1.5 Pro и Flash — это абсолютные лидеры в размере контекста. Размер контекста в 15 раз больше по сравнению с большинством конкурентных моделей от других разработчиков. Это делает Gemini 1.5 Pro уникальным на рынке, способным обрабатывать колоссально большие объёмы данных в одном запросе.
Место №4. Anthropic
Anthropic уверенно держит свои позиции на рынке ИИ благодаря моделям серии Claude 3. Эти языковые модели созданы с акцентом на безопасность, точность и устойчивость в работе с данными. Anthropic ориентируется на создание систем, которые могут быть применены как в коммерческих, так и научных задачах, обеспечивая высокий уровень контроля над результатами и сниженную вероятность генерации опасных или некорректных данных.

Последние версии
Claude 3.5 Sonnet — это флагманская модель Anthropic, обладающая впечатляющей вычислительной мощностью и оптимизированная для выполнения сложных задач. Она справляется с генерацией текстов, обработкой больших объемов данных, а также может использоваться в системах, требующих высокого уровня интеллектуальной поддержки принятия решений.
Claude 3 Opus — более сбалансированная версия, предлагающая компромисс между производительностью и экономией ресурсов. Она ориентирована на задачи средней сложности, такие как анализ данных, разработка интеллектуальных систем поддержки пользователей и автоматизация процессов.
Claude 3 Haiku — это самая компактная версия из серии, которая предназначена для менее ресурсоемких приложений, таких как чат-боты и обработка небольших текстовых запросов. Haiku демонстрирует высокую скорость выполнения задач и может быть эффективна использована там, где не требуются мощные вычислительные ресурсы.
Сравнение версий
Сравним все четыре версии по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
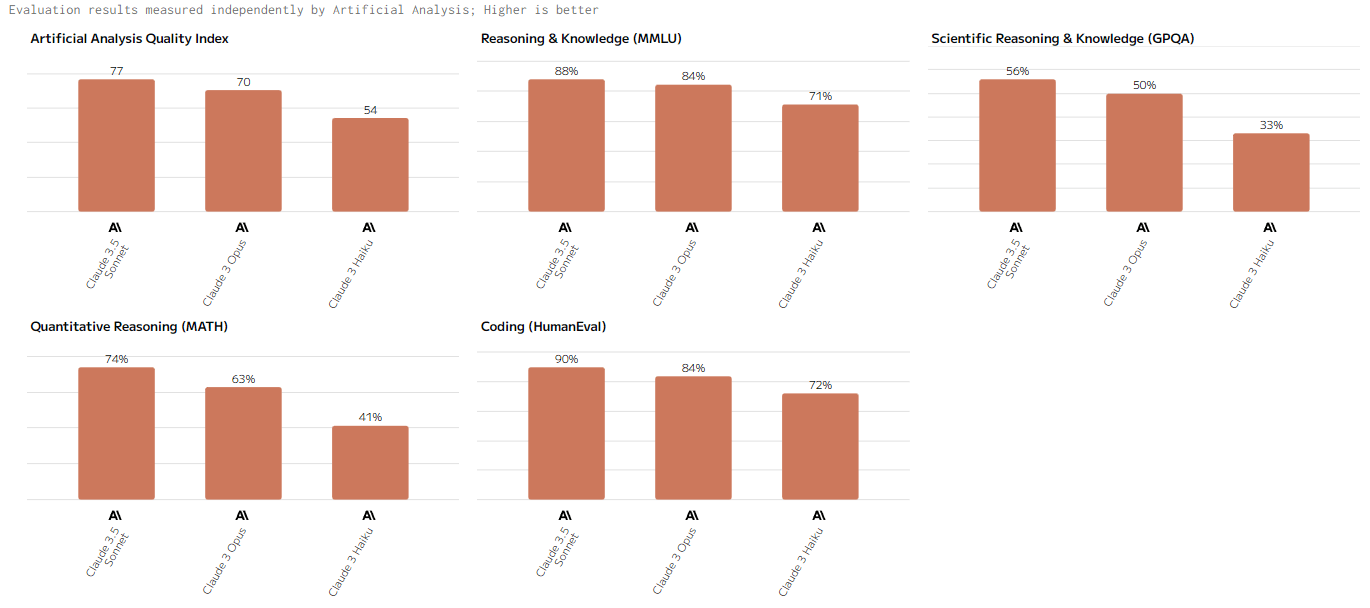
Индекс качества (Artificial Analysis Quality Index)
Claude 3.5 Sonnet лидирует в этой категории, демонстрируя высокие результаты в сложных задачах, таких как текстовая генерация, глубокий анализ данных и решение логических проблем. Claude 3 Opus и Claude 3 Haiku показывают достойные результаты, но уступают старшей модели по точности и глубине обработки данных.
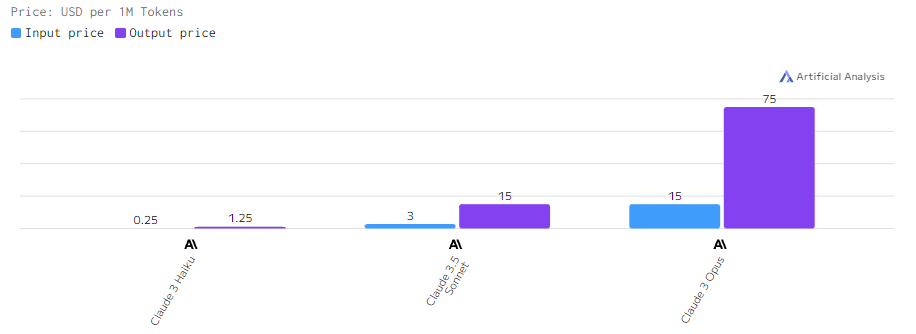
Стоимость
Стоимость за обработку токенов возрастает с увеличением вычислительной мощности модели. Claude 3.5 Sonnet является самой дорогой среди моделей Anthropic, тогда как Claude 3 Haiku предлагает максимально экономичный вариант для менее требовательных приложений.
Задержка
Задержка у Claude 3.5 Sonnet выше из-за более сложных алгоритмов обработки, тогда как Claude 3 Haiku демонстрирует минимальную задержку и быструю реакцию, что делает её идеальной для интерактивных задач. Примечательно то, что самая высокая задержка не у Sonet, а у Opus, уступающей ей по ряду основных параметров модели.

Контекстное окно
Для всех моделей серии Claude 3 контекстное окно ограничивается 200k, что выше среднего. Однако такие цифры уже не впечатляют после 2-х миллионов Gemini 1.5 Pro и миллиона Flash.
Место №5. Mistral AI
Mistral AI стремительно завоевывает популярность благодаря своим мощным языковым моделям, ориентированным на высокую производительность и гибкость применения. Основное преимущество моделей Mistral заключается в их способности эффективно обрабатывать задачи, требующие глубокого анализа данных, генерации текстов и программирования. Компания активно разрабатывает модели для научных, коммерческих и исследовательских проектов, обеспечивая баланс между производительностью и экономичностью.

Последние версии
Mistral Large 2 — это самая мощная версия, обладающая улучшенной архитектурой и оптимизированной для работы с большими объёмами данных. Модель справляется с широким спектром задач, включая глубокий анализ текстов и генерацию программного кода.
Mixtral 8x22B представляет собой гибридную модель, состоящую из восьми сателлитных моделей, каждая из которых имеет 22 миллиарда параметров. Этот подход позволяет обеспечить высокую производительность и распределённую обработку данных, что делает Mixtral 8x22B особенно эффективной для многозадачных приложений и проектов, связанных с машинным обучением.
Mistral Small — это наименее ресурсоёмкая версия, созданная для выполнения задач с ограниченными вычислительными ресурсами. Модель идеально подходит для приложений, таких как чат-боты и простая генерация текстов, сохраняя при этом высокое качество обработки данных.
Сравнение версий
Сравним все четыре версии по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
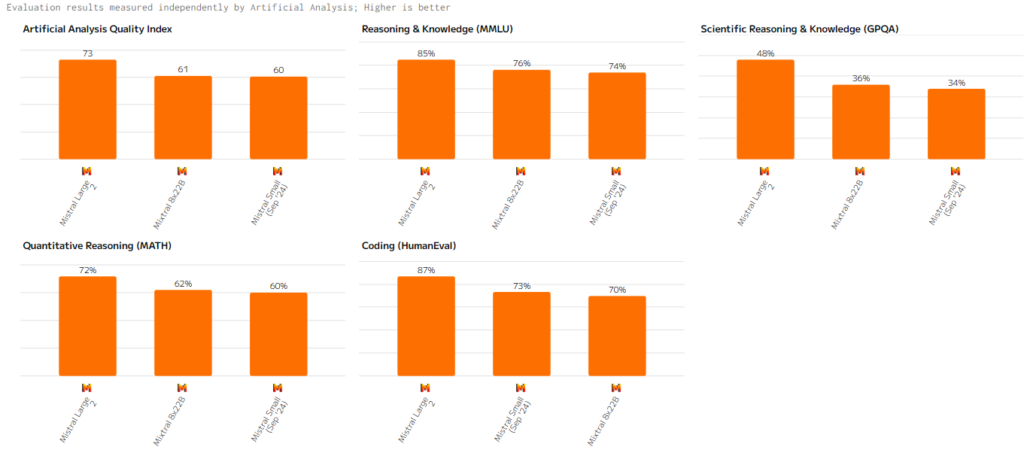
Индекс качества (Artificial Analysis Quality Index)
Mistral Large 2 лидирует среди моделей компании, демонстрируя высокую точность и глубокую обработку данных. Mixtral 8x22B также показывает высокие результаты, особенно в задачах, связанных с параллельной обработкой данных. Mistral Small остаётся эффективной для логических задач не требующих больших мощностей, и, между прочем, обгоняет Mixtral 8x22B в Coding.
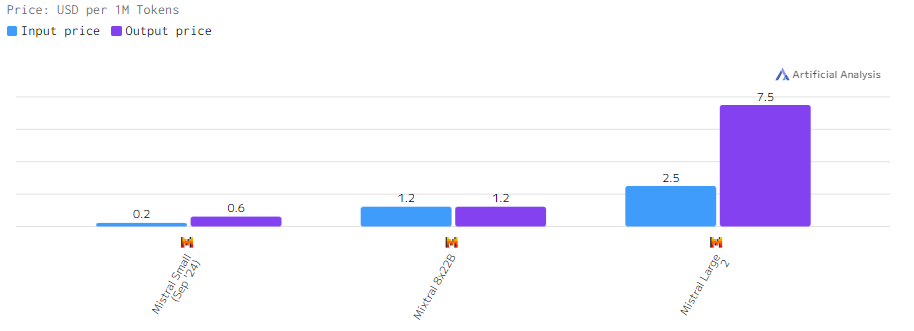
Стоимость
Стоимость моделей Mistral зависит от их производительности. Mistral Large 2 является самой дорогой моделью, в то время как Mistral Small предлагает экономичный вариант для проектов с ограниченными ресурсами.
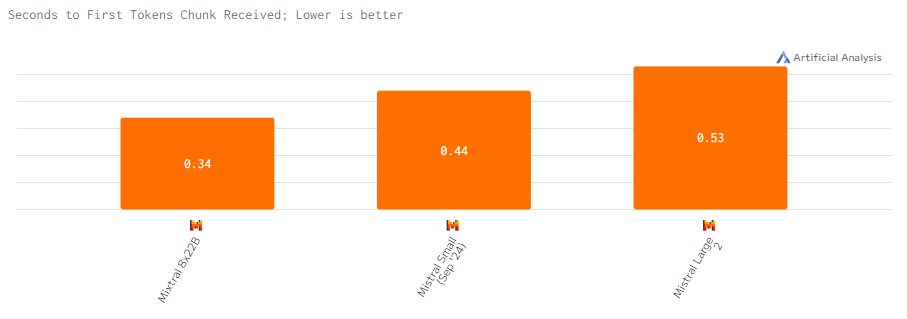
Задержка
Задержка у Mistral Large 2 выше из-за её мощности и сложности обработки данных. Mistral Small показывает более быструю реакцию, а Mixtral 8x22B демонстрирует самую высокую скорость реакции благодаря распределённой обработке.
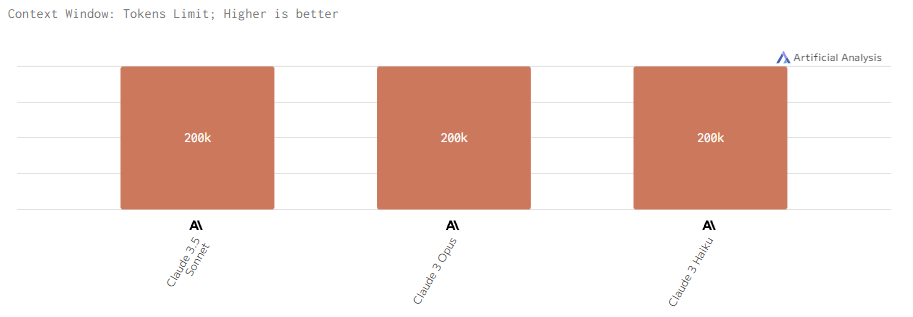
Контекстное окно
Mistral Large 2 и Mistral Small поддерживают стандартное контекстное окно размером 128k. Mixtral 8x22B обладает сокращенным контекстным окно в 65.4k.
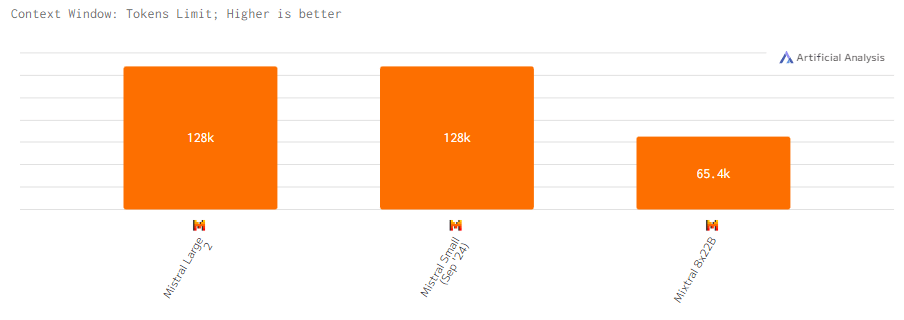
Место №6. Deepseek
Deepseek предлагает рынку специально разработанных для кодирования и обработки естественного языка ИИ-модели — DeepSeek-Coder-V2, DeepSeek-V2, DeepSeek-V2.5. Эти модели отлично справляются с программированием и математикой.
![]()
![]()
Последние версии
DeepSeek-Coder-V2 — это самая мощная версия в линейке DeepSeek, специально разработанная для задач программирования и обработки естественного языка. Модель демонстрирует высокие результаты в решении логических задач и программировании, что делает её хорошим выбором для разработчиков и исследователей.
DeepSeek-V2 обеспечивает отличное качество обработки естественного языка и решение математических задач. Эта модель хорошо подходит для выполнения задач, связанных с математикой и анализом данных, сохраняет высокую производительность и эффективность в выполнении задач.
DeepSeek-V2.5 представляет собой более оптимизированную версию моделей V2 для выполнения задач, связанных с программированием и анализом данных. Она показывает эффективное решение задач с логикой, хотя и уступает DeepSeek-Coder-V2.
Сравнение версий
Мы сравним три модели по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
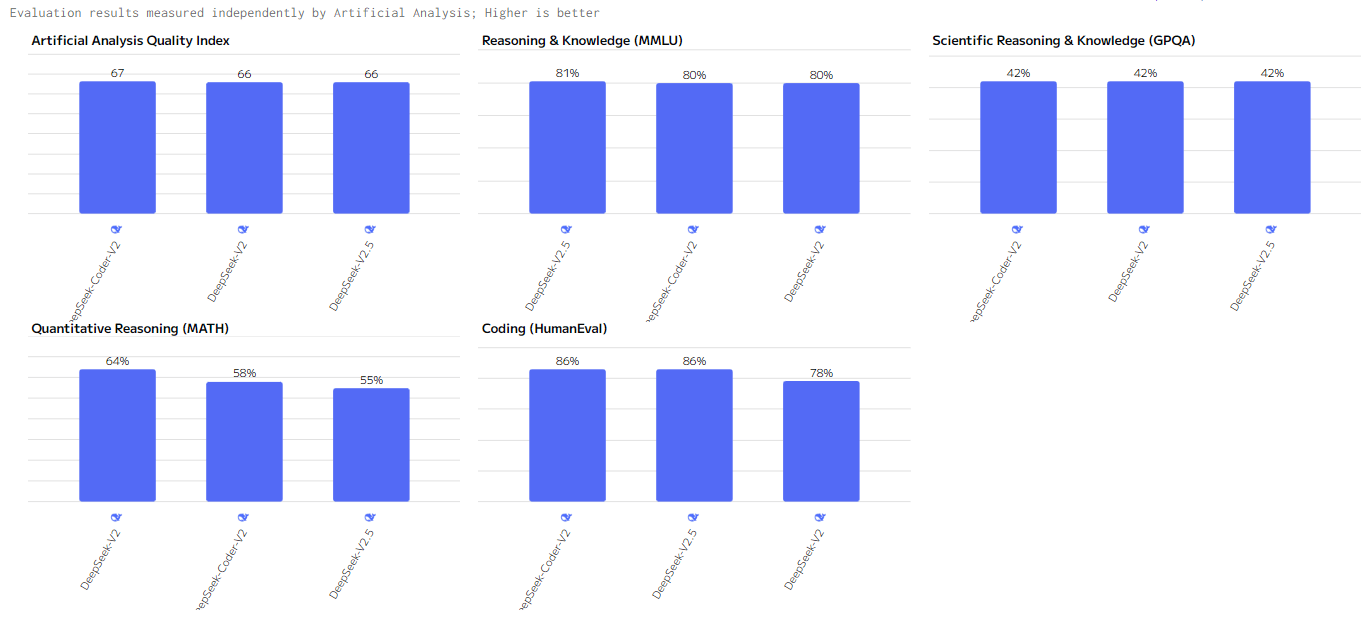
Индекс качества (Artificial Analysis Quality Index)
DeepSeek-Coder-V2 лидирует в данной категории, показывая отличные результаты в программировании, решении логических и математических задач. DeepSeek-V2 и DeepSeek-V2.5 демонстрируют практически те же результаты, однако уступают DeepSeek-Coder-V2 в Coding и частично в MATH показателях.
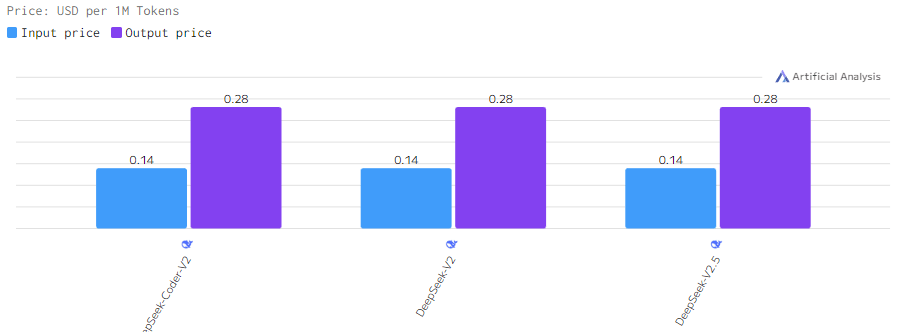
Стоимость
Стоимость всех трех моделей одинаковая.
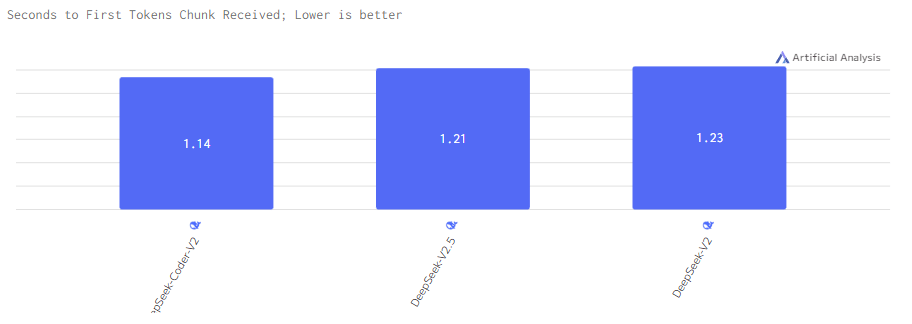
Задержка
Задержка у DeepSeek-V2 чуть выше чем у DeepSeek-V2.5 и Coder-V2.
Контекстное окно
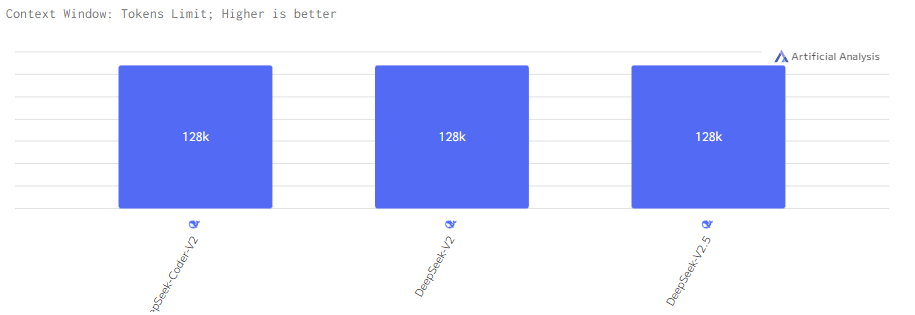
Все модели поддерживают контекстное окно размером 128k. Контекста хватит обеспечивать эффективную обработку длинных запросов и больших объемов данных.
Место №7. AI21 labs
AI21 Labs предлагают пользователям эффективные инструменты для решения задач в области обработки естественного языка. Jamba 1.5 находят применение в разнообразных сферах, от создания контента до анализа данных, обеспечивая хорошую производительность и неплохую точность.

Последние версии
Jamba 1.5 Large представляет собой сильную ИИ-модель, специально разработанное для выполнения сложных текстовых запросов и обработки больших массивов данных.
Jamba 1.5 Mini является более компактной версией, которая сохраняет основные преимущества своей старшей модели, но с меньшими требованиями к вычислительным ресурсам. Эта модель идеально подходит для задач, не требующих высокой вычислительной мощности, таких как автоматизация ответов на стандартные запросы или простая генерация текстов.
Сравнение версий
Мы сравним три модели по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
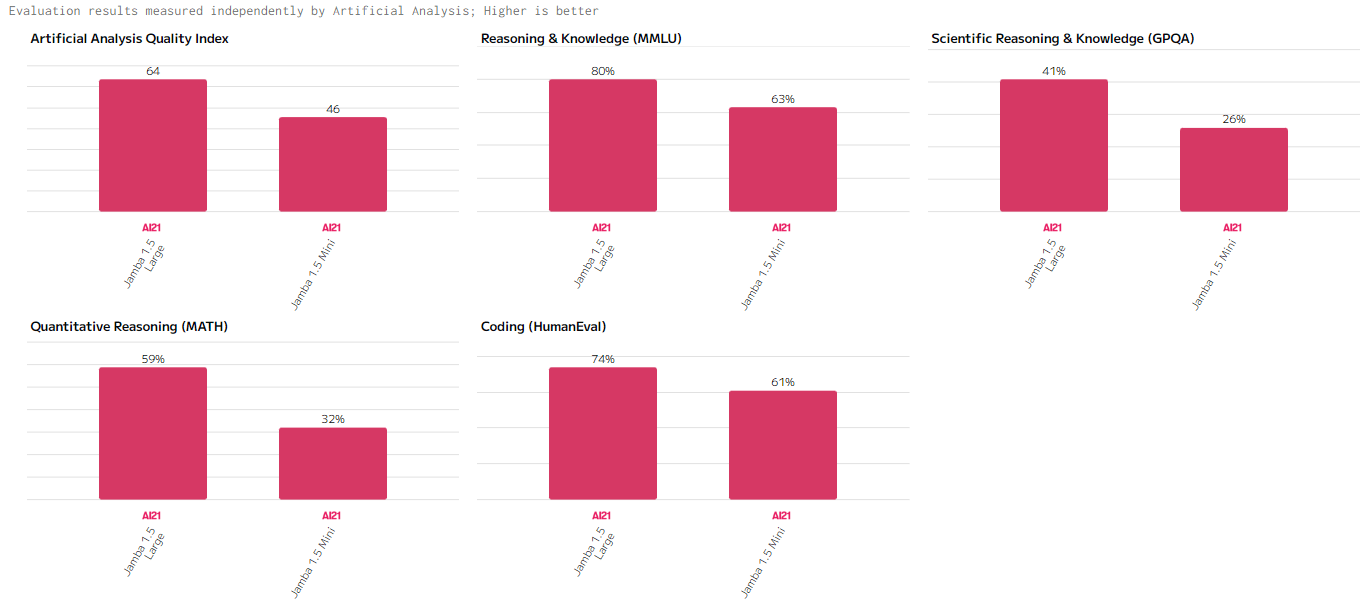
Индекс качества (Artificial Analysis Quality Index)
Jamba 1.5 Large показывает хорошие показатели в обработке сложных аналитических задач и создании содержательных текстов. В свою очередь, Jamba 1.5 Mini показывает хорошую эффективность в более простых сценариях, хотя и не достигает уровня старшей модели по точности и глубине анализа.
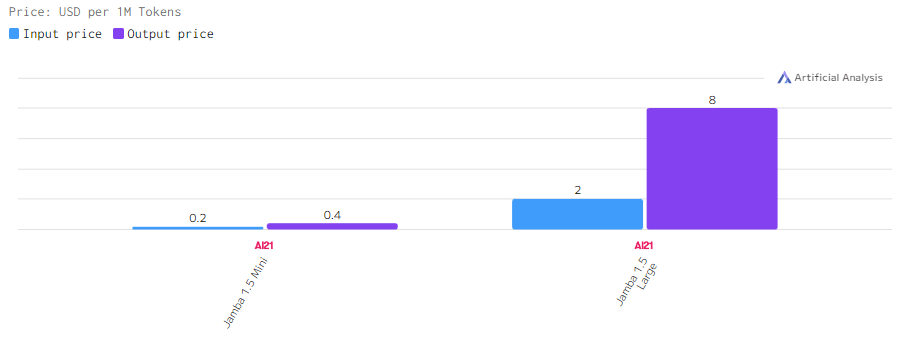
Стоимость
Стоимость Jamba 1.5 Large дороже Mini-версии, которая предлагает функционал для пользователей с ограниченным бюджетом или низким запросом.
Задержка
Задержка у Jamba 1.5 Large маленькая, но все же выше Jamba 1.5 Mini.
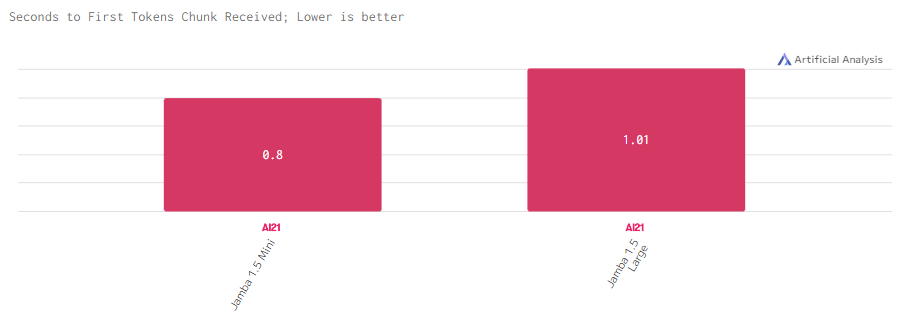
Контекстное окно
Jamba 1.5 Large и Jamba 1.5 Mini работают с действительно большим контекстом в 256k, что наверянка позволяет эффективно обрабатывать длинные запросы и большие объёмы данных.
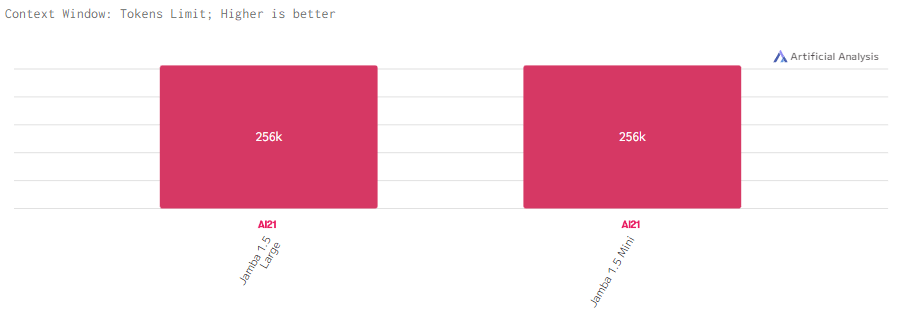
Место №8. Perplexity
Perplexity развивает свои языковые модели, предлагая решения, ориентированные на обработку естественного языка и взаимодействие с пользователями. Компания фокусируется на создании моделей, которые способны обеспечивать хорошую точность и эффективность в различных приложениях, включая чат-боты, автоматизацию обработки данных и генерацию контента.

Последние версии
Sonar Large является самой мощной моделью компании, обладающей значительной вычислительной мощностью и предназначенная для выполнения сложных задач. Она демонстрирует отличные достойные результаты в текстовой генерации и обработке больших объемов информации, что делает её подходящей для применения в аналитике и интеллектуальных системах.
Sonar Small — облегченная версия, которая сохраняет многие функции своей старшей модели, но с меньшими требованиями к ресурсам. Эта модель отлично подходит для задач, где важна скорость обработки и экономия вычислительных ресурсов, таких как чат-боты и генерация простых запросов.
Сравнение версий
Сравним все четыре версии по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
Индекс качества (Artificial Analysis Quality Index)
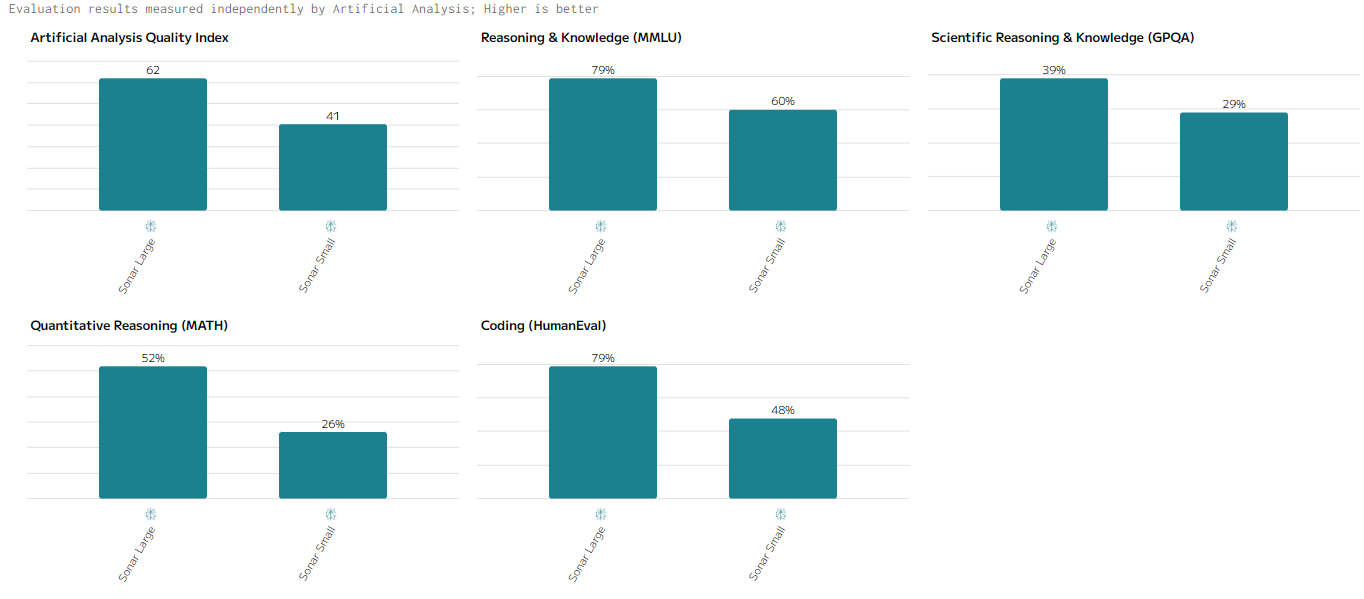
Sonar Large демонстрирует хорошие результаты в математике и программировании. Результаты в текстовой генерацией и глубоким анализом данных тоже весьма неплохие. Sonar Small показывают скромные результаты, что связано с меньшими вычислительными возможностями.
Стоимость
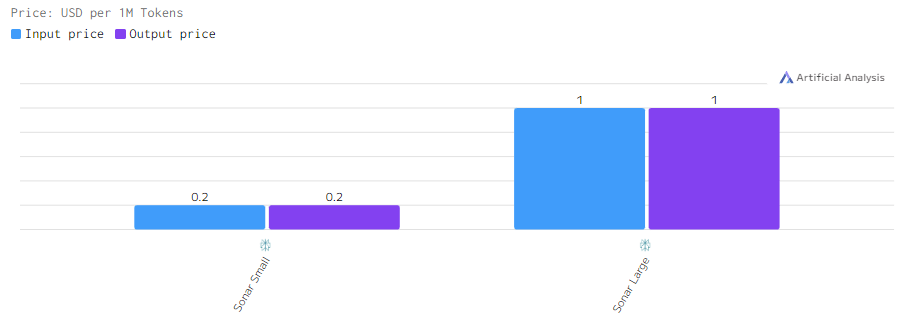
Цены на модели Sonar Large выше из-за её высокой производительности и вычислительной мощности, в то время как Sonar Small предлагает более доступные варианты для ограниченных бюджетов.
Задержка
Sonar Large демонстрирует схожие с Sonar Small показатели задержки. Высокая скорость моделей Sonar оптимальна для интерактивных задач.
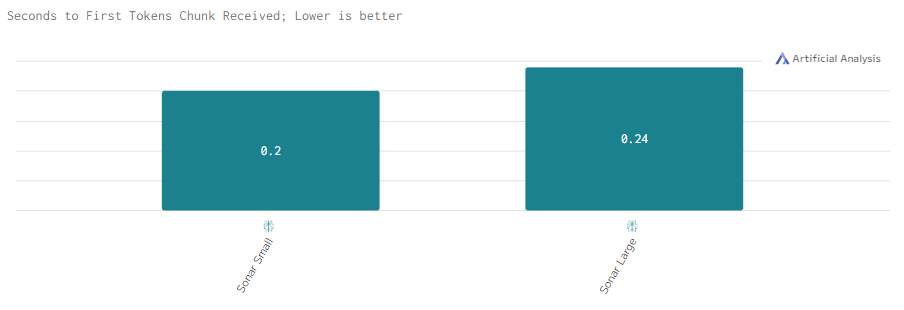
Контекстное окно
Модели поддерживают контекстное окно размером 32k. Этого контекста вполне хватает для простых и продвинутых запросов, однако с длинными запросами анализа здоровых блоков информации могут возникнуть галлюцинации.
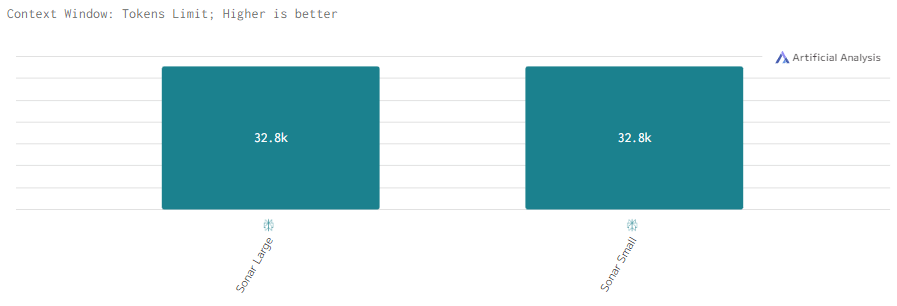
Место №9. Reka
Reka, с её моделями Reka Core, Reka Flash и Reka Edge, постепенно набирает обороты в мире языковых моделей, предлагая уникальные решения для различных задач. БReka становится всё более востребованной как в бизнесе, так и в научных кругах. Эти модели охватывают широкий спектр приложений — от высокоточных вычислений до обработки больших массивов данных и автоматизации процессов.
![]()
![]()
Последние версии
Reka Core — это основная и наиболее мощная модель от Reka, оптимизированная для решения сложных задач с большими вычислительными требованиями. Хороший вариант для анализа данных, работы мультимодальными входами.
Reka Flash — облегчённая версия Core, предназначенная для задач, где важна скорость обработки данных и экономия вычислительных ресурсов. Она может применяться для чат-ботов, автоматизации простых процессов и генерации текста. Flash сохраняет большую часть возможностей старшей модели, но фокусируется на более быстрых и экономичных решениях.
Reka Edge — модель, ориентированная на работу в распределённых системах и на устройствах с ограниченными вычислительными ресурсами. Эта версия отлично подходит для задач с низким потреблением мощностей.
Сравнение версий
Мы сравним три модели по следующим показателям: Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
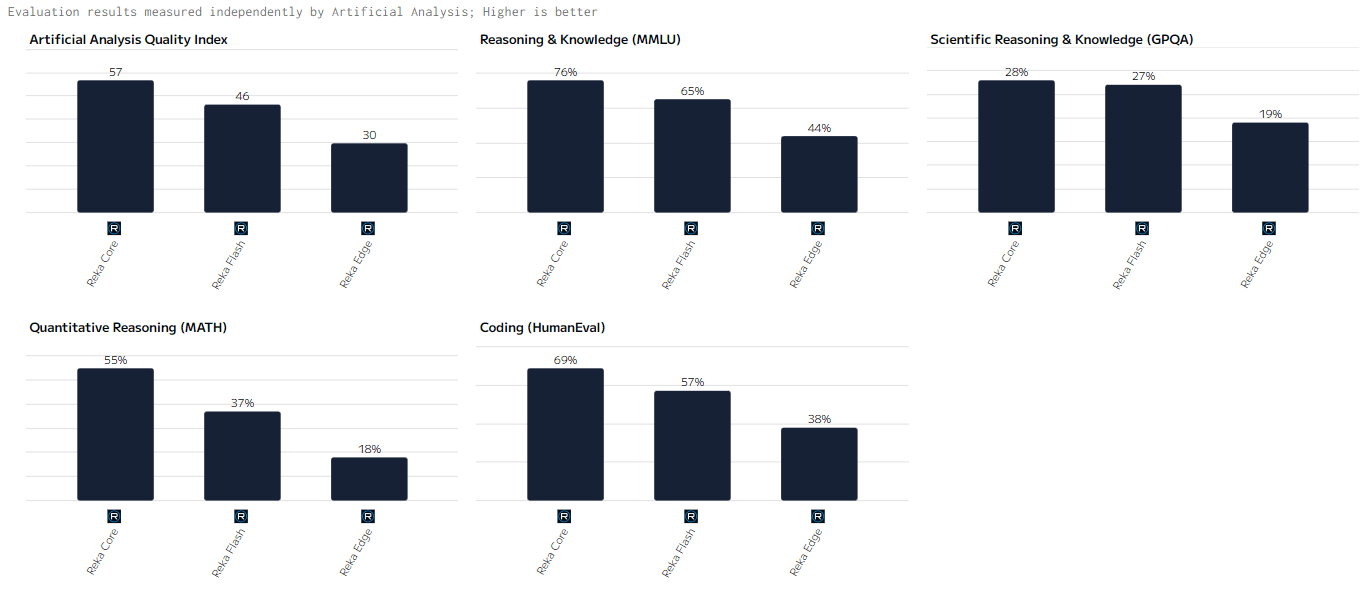
Индекс качества (Artificial Analysis Quality Index)
Reka Core демонстрирует наивысшие показатели среди моделей, особенно в задачах, связанных с глубокой обработкой данных и мультимодальными запросами. Reka Flash, хотя и уступает Core по точности, всё же демонстрирует высокие результаты в задачах средней сложности. Reka Edge предлагает приемлемую производительность для менее сложных задач, где важна стабильность и низкое энергопотребление.
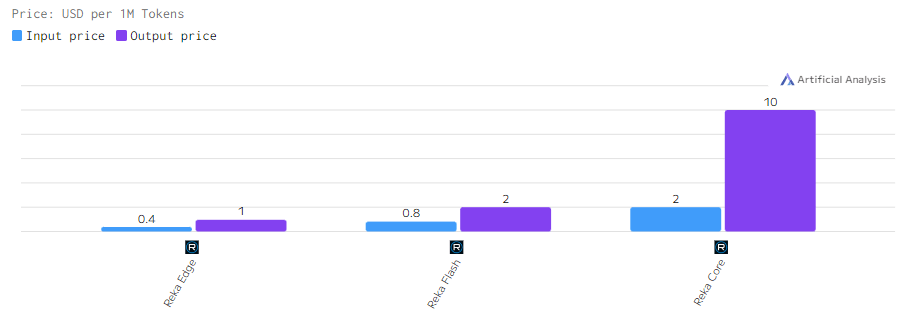
Стоимость
Стоимость на использование моделей Reka варьируется в зависимости от их вычислительных возможностей. Reka Core стоит дороже, так как она требует больше ресурсов для выполнения сложных операций. Reka Flash и Edge, в свою очередь, представляют более экономичные варианты для применения в проектах с ограниченными бюджетами.
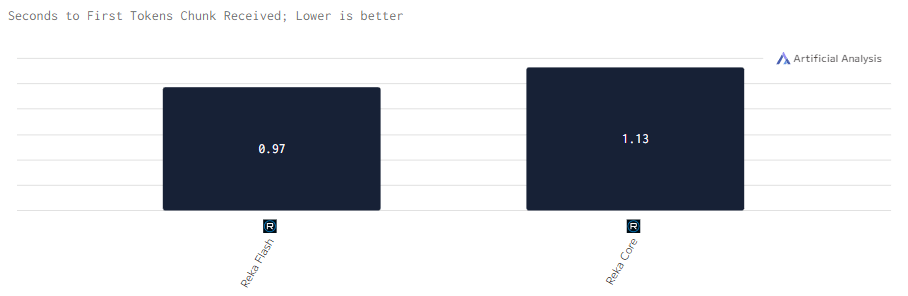
Задержка
Reka Core имеет небольшую задержку, но Reka Flash работает еще быстрее, что делает её востребованнее для задач, где требуется быстрая реакция.
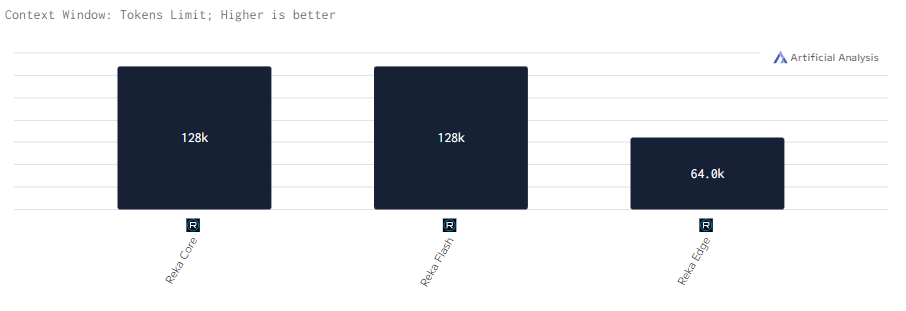
Контекстное окно
Все модели Reka поддерживают контекстное окно размером 128k, за исключением Edge, у которой оно в 2 раза меньше. Однако что 128k, что 64k позволяют эффективно работать с длинными текстами и сложными запросами.
Место №10. Cohere
Cohere старается укреплять свои позиции на рынке благодаря развитию моделей, оптимизированных для выполнения команд и обработки естественного языка. Основное внимание компания уделяет производительности и точности при выполнении текстовых задач, таких как генерация, редактирование и анализ данных.

Последние версии
Command-R+ — это флагманская модель Cohere, которая предлагает улучшенные возможности по работе с большими объёмами данных и сложными текстовыми запросами. Модель оптимизирована для выполнения команд, требующих высокой точности и контекстуального понимания, что делает её достойным решением для интеллектуальных систем поддержки принятия решений и анализа данных.
Command-R — это более доступная по ресурсам версия, которая также демонстрирует высокую производительность, но при этом ориентирована на задачи средней сложности. Command-R отлично подходит для автоматизации бизнес-процессов и обработки стандартных текстовых запросов, сохраняя при этом высокий уровень точности.
Сравнение версий
Сравним все четыре версии по следующим показателям:Индекс качества (Artificial Analysis Quality Index), Стоимость, Задержка, Контекстное окно.
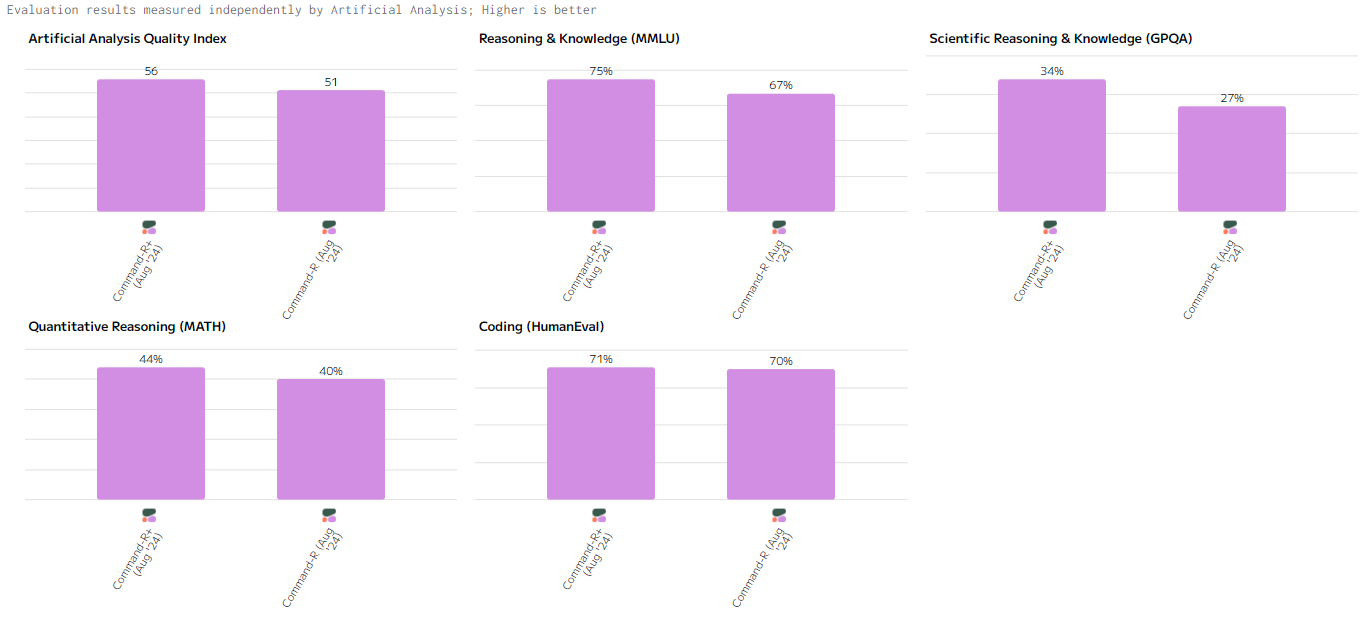
Индекс качества (Artificial Analysis Quality Index)
Command-R+ демонстрирует сильные результаты в задачах, требующих глубокого анализа и математической логики, тогда как Command-R показывает несколько сниженные, но всё ещё достойные, особенно в Coding, результаты для менее сложных приложений.
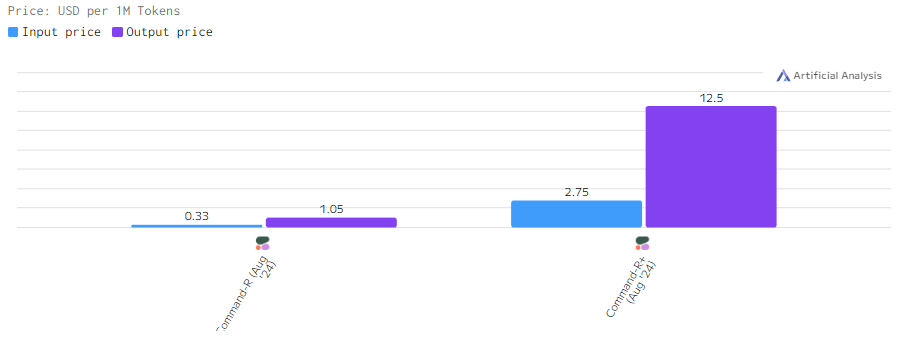
Стоимость
Модель Command-R+ кратно дороже своей старой версии из-за её вычислительной мощности, тогда как Command-R предлагает более экономичный вариант для проектов с меньшими требованиями к ресурсам.
Задержка
Задержка у Command-R+ несколько выше, тогда как Command-R демонстрирует более быструю реакцию и меньшую задержку.
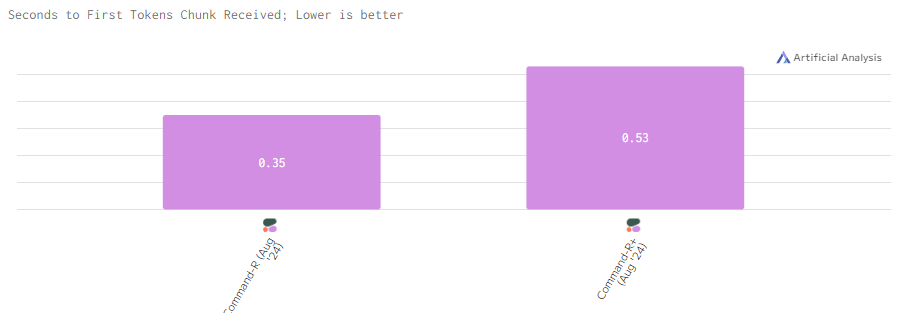
Контекстное окно
Обе модели работают в контексте 128k. Этого вполне хватает для эффективной обработки длинных запросов с большими объёмами данных, обеспечивая высокую производительность в работе с текстами.
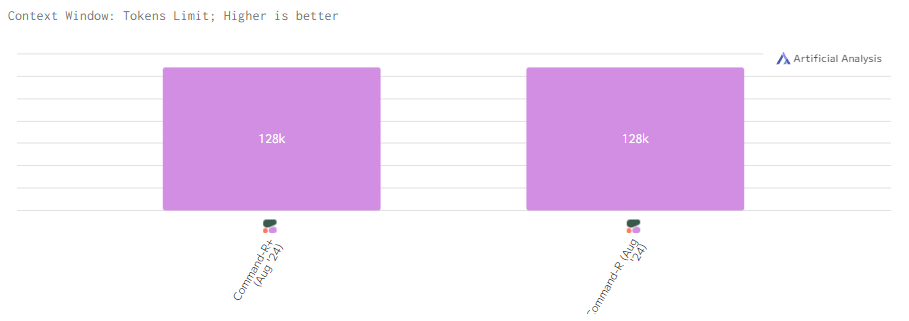
Критерии сравнения
Индекс качества (Artificial Analysis Quality Index): Это средний результат, основанный на оценках, охватывающих различные аспекты интеллекта модели. Он включает в себя следующие четыре критерия:
- Понимание языка и рассуждения (Reasoning & Knowledge, MMLU): Этот тест предназначен для оценки способности языковых моделей выполнять широкий спектр задач, связанных с пониманием языка. Он включает в себя множество предметных областей и типов вопросов, от простых до сложных, что позволяет оценить универсальность модели.
- Научное рассуждение и знание (Scientific Reasoning & Knowledge, GPQA): Критерий измеряет способности модели отвечать на научные и технические вопросы, включая анализ и интерпретацию данных, что важно для научных и исследовательских приложений
- Решение математических задач и математическая логика (Quantitative Reasoning, MATH): Этот критерий фокусируется на оценке математических навыков модели. Тест включает в себя решение уравнений, выполнение арифметических операций и более сложные математические задачи, что позволяет оценить способность модели работать с числовыми данными и формулами.
- Генерация кода на основе текста (Coding, HumanEval): Тест оценивает способность модели генерировать код на основе текстовых описаний. Задачи в HumanEval охватывают различные уровни сложности и требуют от модели как понимания, так и генерации программного кода.
Стоимость: Это цена за токен, представляемая в долларах США за миллион токенов. Стоимостью является комбинацией цен на входные и выходные токены с соотношением 3:1. Этот показатель важен для компаний и разработчиков, так как помогает оценить стоимость использования модели в зависимости от объёма данных, которые она обрабатывает.
- Входящая стоимость: Стоимость за токен, включенный в запрос/сообщение, отправляемое в API, $/1 миллион токенов.
- Выходящая стоимость: Стоимость за токен, сгенерированный моделью (полученный через API), $/1 миллион токенов.
Задержка: Это время, необходимое для получения первого токена после отправки запроса к API, измеряемое в секундах. Для моделей, которые не поддерживают потоковую передачу, данный показатель отражает время, необходимое для получения полного ответа.
Токен — это минимальная единица текста, которая используется в обработке естественного языка моделями ИИ. Токен может быть отдельным словом, частью слова или даже символом, в зависимости от языка и структуры текста.
Контекстное окно: Это максимальное количество токенов, которое может быть использовано в совокупности для входных и выходных данных. Он определяет, сколько информации модель может обрабатывать одновременно.
Заключение
В 2024 году рынок больших языковых моделей продемонстрировал впечатляющий рост и разнообразие. Одни выделяются своей производительностью и ресурсоемкостью, другие — скоростью и экономией мощностей. Что их объединяет, так это наличие своих уникальные преимущества, позволяющих пользователям выбрать наиболее подходящее решение для конкретных задач.
В целом, использование языковых моделей открывает новые горизонты в автоматизации и повышении эффективности. Благодаря их способности к анализу, генерации текста и решению сложных задач, компании могут значительно улучшить взаимодействие с клиентами и оптимизировать внутренние процессы. Выбор модели должен основываться на четком понимании целей, будь то обработка естественного языка, научные исследования или разработка ПО.







